QCon Conference. Mastering Chaos: Netflix’s Guide to Microservices. Part 2
QCon Conference. Mastering Chaos: Netflix’s Guide to Microservices. Part 1
To protect applications from this kind of problems, we developed HYSTRIX – the implementation of the corporate Circuit Breaker template, a fuse that controls delays and errors during network calls.

HYSTRIX is a fault tolerance library that will fail to a threshold, leaving the circuit open. This means that HYSTRIX will redirect all subsequent calls to the reserve to prevent future failures, and will create a temporary buffer for the corresponding service, which can be restored after the failure. This is something like a fallback: if service A cannot call service B, it will still send a backup response to the client, which will allow it to continue using the service instead of just receiving an error message.
Thus, the advantage of HYSTRIX is its isolated thread pools and the concept of chain. If several calls to service B are unsuccessful, service A will stop making them and will wait for recovery. At one time, HYSTRIX was an innovative solution, but when it was used, the question arose: I have an entire history of settings, I’m sure everything is done correctly, but how do I know if it really works?
The best way to find out (remember our biological analogies) is to vaccinate when you take a dead virus and introduce it into the body to stimulate the antibodies to fight the living virus. In production, the role of vaccination is played by the Fault Injection Testing (FIT) framework – testing that allows you to find microservice problems by creating artificial failures. With it, synthetic transactions are performed at the device or account level, or the volume of “live” traffic is increased up to 100%. In this way, the reliability of microservices under stress is checked.
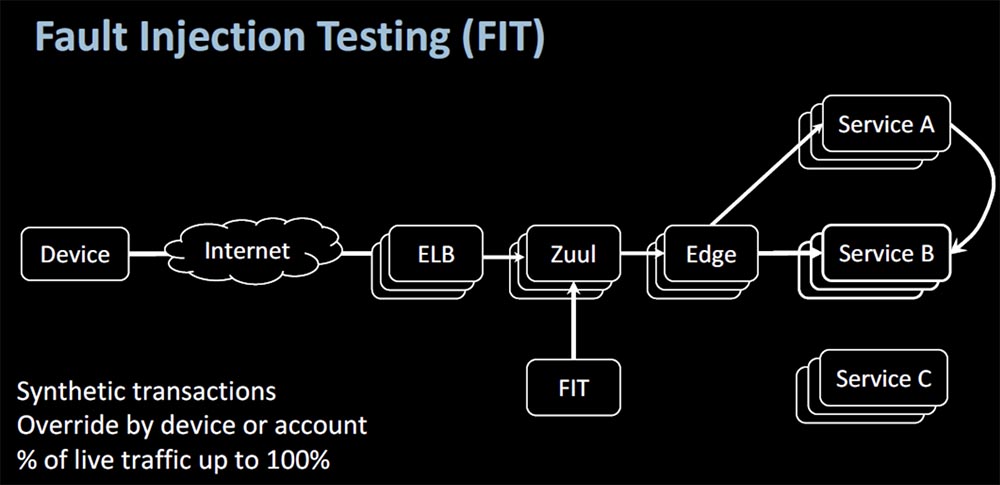
Of course, you want to test the service call, direct or indirect, you want to make sure that your requests are decorated with the correct context. That is, with the help of FIT, you can “bring down” the service and analyze the causes of malfunctions without a real production failure.
This is good when considering point-to-point connections. But imagine that your system consists of hundreds of microservices, and each of them depends on the others. How to test such a system without conducting millions of tests during which services call each other?
Suppose you have 10 services in a single microservice structure, and each of them has 99.99% availability. This means that over the course of a year, each service may not be available for 53 minutes.

If the services worked independently, this would not be anything critical, but when they depend on each other, the total failure time of the entire microservice can reach 8-9 hours per year, and this is already a big difference.
From the foregoing, the concept of critical microservices arises – this is the minimum level of service that a client would like to receive in the event of a failure, i.e., the basic ability to view content, for example, from a list of only popular films. Customers will put up with the loss of some additional services, such as personalization, while they can achieve even that. Using this approach, we identified such services and grouped them, creating a “FIT recipe”. In fact, this is a “black list”, which includes all other services that are not critical.

After that, we tested the product and made sure that in this way we ensured the constant availability of critical services in case of loss of other functions. So we managed to get rid of hard dependencies.
Let’s talk about client libraries. We discussed quite sharply about them when we started the transition to cloud technologies. At that time, many people from Yahoo came to our team who were categorically against client libraries, advocating the maximum simplification of the service to “bare iron”.
Imagine that I have common logic and common access patterns for calling my service and there are 20 or 30 different dependencies. Do I really want each individual development team to write the same or slightly different code again and again, or do I want to combine everything into a common business logic and common access patterns? It was so obvious that we implemented just such a solution.
The problem was that we actually rolled back, creating a new kind of monolithic structure. In this case, the API gateway, which interacts with hundreds of services, launched a huge amount of code, which led us to the situation in 2000, when the same bunch of code used a common code base.
This situation is similar to a parasitic infection. The ugly creature on the slide has no Godzilla size and is not capable of destroying Tokyo, but it will infect your intestines, which are suitable for blood vessels, and begin to drink your blood like a vampire. This will lead to anemia and greatly weaken your body.

Likewise, client libraries can do things that you don’t know about and that can weaken your service. They may consume more heat than you expect, they may have logical defects leading to malfunctions. They may have transit dependencies that attract other libraries of conflicting versions and break the account system. All this happens in reality, especially in the API team, because they use libraries of other development teams.
There can be no single solution, therefore, as a result of disputes and discussions, we reached a consensus, which consisted in an attempt to simplify these libraries.

We had no desire to leave one “bare metal”, we wanted to use simple logic with common patterns. As a result, a balance was found between the extremely simple framework REST API model and the most simplified client libraries.
Let’s talk about Persistence, a system survivability. We chose the right path, taking as a basis the CAP theorem. I see that only a few of those present are unfamiliar with her. This theorem suggests that in the presence of network partitions, one has to choose between consistency and availability. Consistency means that every read gives the latest record, and availability means that every working node always successfully performs read and write requests. This applies to scenarios in which one particular database in the availability zone may not be available, while other databases will be available.
The slide shows network service A, which writes copies of identical data to 3 databases. Each of the bases works with one of 3 networks, providing accessibility. The question is what to do if you lose contact with one of the databases – you will have a failure and an error message, or you will continue to work with the other two databases until the problem is resolved.

As a solution to this issue, Netflix has proposed a “final consistency” approach. We do not expect that each individual record will be immediately read from any source in which we recorded the data, we write further and later fully replicate it in order to achieve data consistency. Cassandra copes with this task perfectly.

It has great flexibility, so the client can only write to one node, which then writes to several other nodes using orchestration. Here comes the concept of local quorum, in which you can say: “I need several nodes to respond and say that they really made this change before I start to assume that it is recorded.” If you are willing to risk reliability, it can be one node providing very high availability, or you can call all nodes and say that you want to record on each of them.
Now let’s talk about infrastructure, because this is a separate important topic. Someday your infrastructure, be it AWS, Google or your own development, may fail, because anything can fail. You see the title of a Forbes article that Amazon AWS crashed Netflix on Christmas Eve 2012.

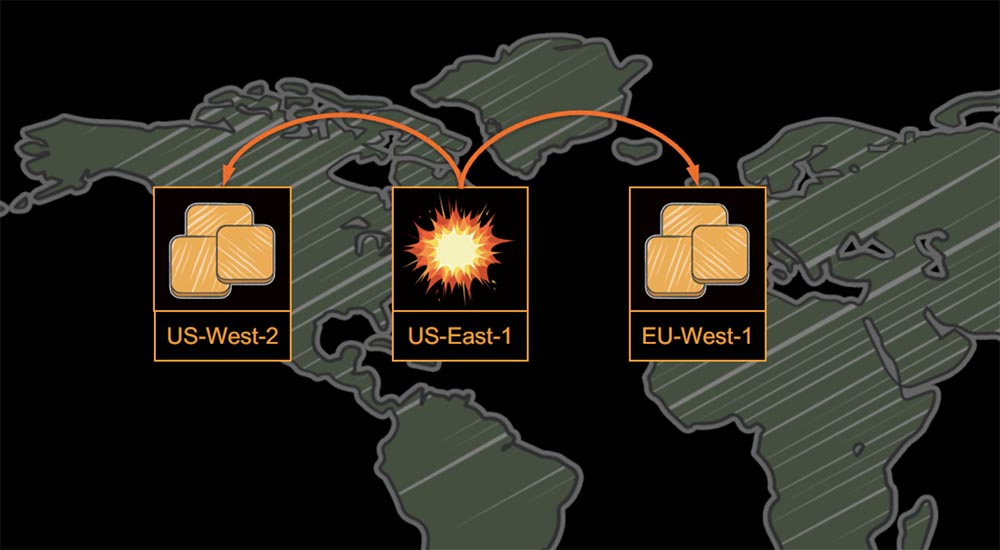
It would be a mistake if I tried to blame it on someone else, because we ourselves put all the eggs in one basket.

We put all of our services on the US-East-1 server, and when the crash happened there, we had nowhere to retreat. After this incident, we implemented a multi-regional strategy with three AWS regions so that if one of them failed, we could transfer all traffic to two other regions.
Earlier this year, I spoke at QСon London with a talk on the global architecture of Netflix, so you can watch this talk if you want to delve deeply into the topic.
Let’s move on to scaling and consider its three components: stateless-services, stateful-services and hybrid services. What is a stateless service? Can any of those present give a definition? To begin with, this is not a cache or database where you store a massive amount of information. Instead, you have frequently used metadata cached in non-volatile memory.
Usually you do not have a binding to a specific instance, that is, you do not expect the client to be constantly bound to a specific service. Most importantly, node loss is not a critical event to worry about. Such a network is restored very quickly, and a failed node is replaced almost instantly by a new one. The most suitable strategy for this is replication. Returning to biology, we can say that we have mitosis, when cells constantly die and are constantly born.
26:30 min
To be continued very soon …
Some advertising
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to your friends, cloud VPS for developers from $ 4.99, A unique analogue of entry-level servers that was invented by us for you: The whole truth about VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps from $ 19 or how to divide the server? (options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
Dell R730xd 2 times cheaper at the Equinix Tier IV data center in Amsterdam? Only here 2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV from $ 199 in the Netherlands! Dell R420 – 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB – from $ 99! Read about How to Build Infrastructure Bldg. class using Dell R730xd E5-2650 v4 servers costing 9,000 euros per penny?