Prometheus and VictoriaMetrics: Resilient Metrics Storage Infrastructure
In this article, my colleague Luca Carboni, DevOps Engineer from Miro’s Amsterdam office, explains what our metrics storage infrastructure looks like. All components in it comply with the principles of high availability (High Availability) and fault tolerance (Fault Tolerance), have a clear specialization, can store data for a long time and are optimal in terms of costs.
The stack in question: Prometheus, Alertmanager, Pushgateway, Blackbox exporter, Grafana, and VictoriaMetrics.
Configuring High Availability and Fault Tolerance for Prometheus
Prometheus Server can use the mechanism federationto collect metrics from other Prometheus servers. It works well if you need to open part of the metrics to tools like Grafana or you need to collect different types of metrics in one place: for example, business metrics and service metrics from different servers.
This approach is widely adopted, but does not follow the principles of high availability and fault tolerance. We work with only a part of the metrics, and if one of the Prometheus servers stops responding, no data will be collected for this period.
There is no ready-made built-in solution to this problem, but to solve it, you do not need to set up complex clusters and come up with complex strategies for server interaction. It is enough to duplicate the configuration file (prometheus.yml) on two servers so that they collect the same metrics in the same way. In this case, server A will additionally monitor server B and vice versa.
The good old principle of redundancy is easy to implement and reliable. If we add an IaC (infrastructure as code) tool like Terraform and a configuration management (CM) system like Ansible to it, then this redundancy is easy to manage and easy to maintain. At the same time, it is possible not to duplicate a large and expensive server, it is easier to duplicate small servers and store only short-term metrics on them. Plus, smaller servers are easier to recreate. Alertmanager, Pushgateway, Blackbox, exporters
Now let’s look at other services in terms of high availability and fault tolerance.
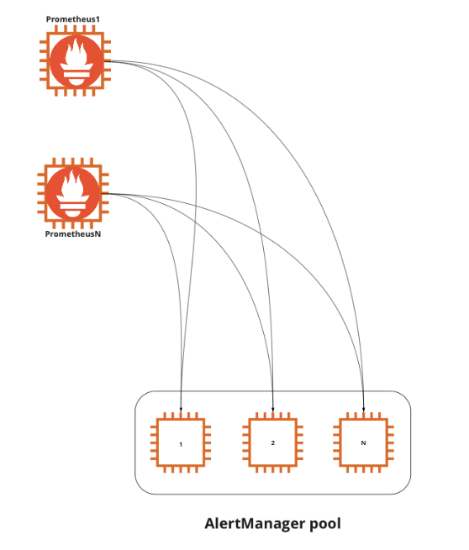
Alertmanager can work in a cluster configuration, is able to deduplicate data from different Prometheus servers and can communicate with other copies of Alertmanager so as not to send multiple identical alerts. Therefore, you can install one copy of Alertmanager on both servers, which we have duplicated: Prometheus A and Prometheus B. And do not forget about the IaC and CM tools to manage the Alertmanager configuration using code.
Exporters installed on specific systems-sources of metrics, they do not need to be duplicated. The only thing to do is to allow the Prometheus A and Prometheus B servers to connect to them.
FROM Pushgateway simple server duplication is not enough, because we get data duplication. In this case, we need to have a single point for receiving metrics. To achieve high availability and fault tolerance, you can duplicate Pushgateway and configure DNS Failover or a balancer so that if one server fails, all requests go to another (active / passive configuration). Thus, we will have a single access point for all processes, despite the presence of several servers.
Blackbox we can also duplicate for Prometheus A and Prometheus B servers.
In total, we have two Prometheus servers, two copies of Alertmanager connected to each other, two Pushgateways in active / passive configuration and two Blackboxes. High availability and fault tolerance are achieved.
It makes little sense to use only these copies to collect all the service metrics. The service can be located on several VPC (Virtual Private Cloud), which can be located in different regions, belong to different accounts and providers. You can even have your own servers. In these cases, the copies will become very large and therefore more difficult to repair. A common practice to achieve high availability and fault tolerance here is to have a separate set of applications for each part of the infrastructure. The principles for dividing the infrastructure into pieces depend on your needs, network and security settings, trust between teams, and so on.
As a result, we have relatively small copies of Prometheus, duplicated along with all the components mentioned above. We have code that can quickly recreate them. And we are not afraid of the failure of one component in each group. It’s definitely better than the plan to “cross your fingers and hope nothing falls”.
VictoriaMetrics for Long Term Data Retention
We tuned Prometheus and its ecosystem to achieve high availability and resiliency. We have several small Prometheus teams with related components, each solving problems in a different part of the infrastructure. This works great for storing data in the short term. For most tasks, we only need to store metrics for 10 days. What if you need to keep your data longer? For example, when you need to find a relationship between different periods – weeks or months. Prometheus can work with long-term data, but the cost will be very high due to the fact that the tool needs to have quick access to it.
This is where Cortex, Thanos, M3DB, VictoriaMetrics and many other tools come to the rescue. All of them are able to collect data from several Prometheus servers, deduplicate them – we will definitely have duplicates, since each of our servers exists in two copies – and provide a single repository for collected metrics.
In this article I will not compare the tools with each other, I will only talk about our experience with VictoriaMetrics…
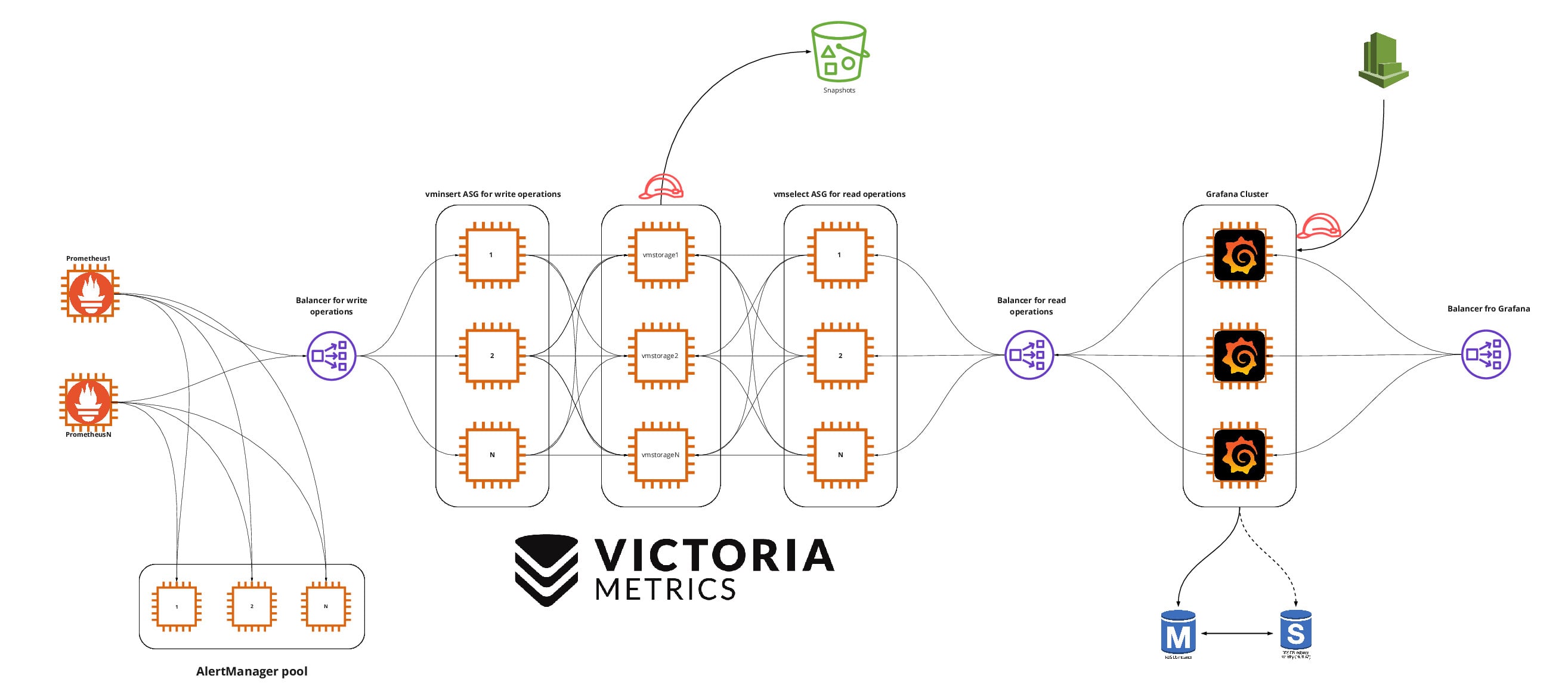
Configuring a cluster version
VictoriaMetrics is available in two versions: a regular all-in-one (single-node version) and a cluster version (cluster version). In the regular version, all components are combined into one application, so the tool is easier to customize, but you can only scale vertically. The clustered version is split into separate components, each of which can be scaled vertically and horizontally.
The regular version is a good and stable solution. But we love to complicate things (heh), so we chose the clustered version.
The clustered version of VictoriaMetrics has three main components: vmstorage (data storage), vminsert (writing data to storage) and vmselect (fetching data from storage). In this form, the tool is very flexible, vminsert and vmselect act as a kind of proxy.
Have vminsert there are many useful configurable options. For the purposes of this article, the important thing is that it can be duplicated any number of times and put a load balancer in front of these copies in order to have a single data point. Have vminsert there is no state (stateless), so it is easy to work with it, easy to duplicate, it is convenient to use in immutable infrastructures and automatic scaling.
The most important parameters to be specified for vminsert Are the storage addresses (storageNode) and the number of storages to which you want to replicate data (replicationFactor = Nwhere N – number of copies vmstorage). But who will send data to the balancer before vminsert? This will be done by Prometheus if we specify the address of the balancer in the settings remote_write…
vmstorage Is perhaps the most important component of VictoriaMetrics. Unlike vminsert and vmselect, vmstorage is stateful and each copy knows nothing about the other copies. Every running vmstorage considers itself an isolated component, it is optimized for cloud storage with high latency (IO latency) and low number of operations per second (IOPS), which makes it significantly cheaper than the storage method used by Prometheus.
The most important settings vmstorage:
storageDataPath – the path on the disk where the data will be stored;
retentionPeriod – data storage period;
dedup.minScrapeInterval – deduplication setting (consider as duplicates those records, the difference between the time stamps of which is less than the specified value).
Each copy vmstorage your data, but thanks to the parameter replicationFactorwhich we specified for vminsert, the same data will be sent to several (N) repositories.
vmstorage can be scaled vertically, you can use more capacious cloud storage, and even for long-term storage of metrics it will be inexpensive, since vmstorage optimized for this type of storage.
vmselect responsible for fetching data from storages. It is easy to duplicate, you can also put a load balancer in front of the created copies in order to have one address for receiving requests. Through this balancer, you can access all the data that has been collected from several Prometheus groups, and this data will be available for as long as you need. The main consumer of this data is likely to be Grafana. Like vminsert, vmselect can be used with auto scaling.

Configuring High Availability and Fault Tolerance for Grafana
Grafana can work both with metrics that Prometheus collects and with metrics that are stored in VictoriaMetrics. This is possible due to the fact that VictoriaMetrics supports, in addition to its own query language (MetricsQL), also PromQL used by Prometheus. Let’s try to achieve high availability and fault tolerance for Grafana.
By default, Grafana uses SQLite to store state. SQLite is development friendly, great for mobile apps, but not great for fault tolerance and high availability. For these purposes, it is better to use a regular DBMS. For example, we can deploy PostgreSQL on Amazon RDS, which uses Multi-AZ technology for availability, and that solves our main problem.
To create a single access point, we can run any number of Grafana copies and configure them to use the same cloud PostgreSQL. The number of copies depends on your needs, you can scale Grafana horizontally and vertically. PostgreSQL can be installed on servers with Grafana, but we are too lazy to do this and like to use the services of cloud providers when they do an excellent job and do not use vendor lock. This is a great example of how you can make life easier.
Now we need a load balancer that will distribute traffic between the Grafana copies. We can additionally bind this balancer to a beautiful domain.
Then it remains to connect Grafana with VictoriaMetrics – or rather, with the balancer before vmselect, – specifying Prometheus as the data source. With this, our monitoring infrastructure can be considered complete.

***
Now all infrastructure components comply with the principles of high availability and fault tolerance, have a clear specialization, can store data for a long time and are optimal in terms of costs. If we want to store the data even longer, we can automatically take pictures on a schedule. vmstorage and send them to Amazon S3 compatible storage.
That’s all about metrics. We still need a system for working with logs, but that’s a completely different story.
Tool list:
Prometheus – https://prometheus.io/
Alertmanager – https://github.com/prometheus/alertmanager
Pushgateway – https://github.com/prometheus/pushgateway
Blackbox exporter – https://github.com/prometheus/blackbox_exporter
Exporters – https://prometheus.io/docs/instrumenting/exporters/
Grafana – https://grafana.com/
VictoriaMetrics – https://victoriametrics.com/
Original article in the English-language blog Miro.