Part 3. Recognizing the time on videos of Dota 2 matches using transformers
In this series of articles, we are implementing a system for automatically searching for highlights in Dota 2 matches. To create it, we need a marked-up dataset with time codes. There are many channels on YouTube where people post cuts of interesting moments from professional Dota 2 matches. Often there are small clocks from the game interface on the video. We will recognize the time on them.

In previous parts:
In the first part, we parsed a replay of one Dota 2 match and found highlights using clustering.
In the second part, we wrote a service for parsing replays in Celery and Flask in parallel.
Under the cut
Download videos from YouTube using
yt-dlp.Sampling frames from the video through
ffmpeg.Cropping the image with
OpenCV.Short review
Tesseract,EasyOCRandTrOCR.We recognize time.
Conclusion.
All links to the code and used materials can be found at the end of the article.
Download videos from YouTube
I used yt-dlp – direct successor youtube-dlwhich is able to bypass the problem of slow loading.
Let’s take the DotA Digest channel as an example and download links to all videos.
yt-dlp \
--print-to-file "%(url)s" youtube/urls.txt \
--flat-playlist https://www.youtube.com/c/DotadigestDDOption --download-sections allows you to download part of the video.
yt-dlp \
--format mp4 \
--download-sections "*00:30-00:45" \
https://youtu.be/wUPhtY4sNP0You can also interact with the utility directly from Python. Let’s write a function that downloads the metadata and saves it to jsonand then downloads the video itself.
...
import yt_dlp
def youtube_download(url):
options = dict(
format="mp4",
outtmpl=f'{VIDEO_DIR}/%(id)s.%(ext)s',
)
with yt_dlp.YoutubeDL(options) as ydl:
info = ydl.extract_info(url, download=False)
video_id = info.get('id')
info_file = f'{video_id}.json'
video_info_path = VIDEO_DIR / info_file
video_file = f'{video_id}.mp4'
video_path = VIDEO_DIR / video_file
if video_path.exists():
logger.info(f'Video already exists: {video_path}')
return video_id
logger.info(f'Downloading: {url}')
with yt_dlp.YoutubeDL(options) as ydl:
ydl.download(url)
with open(video_info_path, 'w') as fout:
json.dump(info, fout, indent=4)
return video_idSampling frames from a video
Usually in video from 24 to 60 FPS (frames per second), while the time on the clock in the game is updated once a second. In order not to process unnecessary images, we will take 1 frame from the video per second. To do this, you can use the utility ffmpeg
ffmpeg -i <video_path> -r 1/1 frames/$filename%03d.bmpThere is a wrapper in Python, but I preferred to hack my version.
import subprocess
def sample_frames(video_id):
video_path = VIDEO_DIR / f'{video_id}.mp4'
output_prefix = FRAMES_DIR / video_id
for file in os.listdir(FRAMES_DIR):
if file.startswith(video_id):
logger.info(f'Frames already exists: {video_id}')
return
logger.info(f'Sampling Frames from: {video_id}')
cmd = f'''ffmpeg \
-i {str(video_path)} \
-r 1/1 \
{str(output_prefix)}__$filename%03d.bmp
'''
subprocess.run(cmd, shell=True)Cropping an image with OpenCV
Often, in optical character recognition (OCR) tasks, you first have to detect a section of the image where there is text, and only then recognize it. We are lucky, the clock in the game interface is a static object. The position may change slightly depending on the screen resolution, but we will ignore this fact.
First, let’s load one frame with OpenCV:
import cv2
import matplotlib.pyplot as plt
image = cv2.imread(str(frame_path))
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)And we will display the result on the screen.
fig = plt.figure(figsize=(10, 10))
plt.imshow(image)
plt.show()
An object image is an array numpywhich allows you to crop and scale the image in just three lines.
bbox = (16, 23, 619, 653)
crop = image[bbox[0]:bbox[1], bbox[2]:bbox[3]]
crop = cv2.resize(crop, dsize=None, fx=16, fy=16, interpolation=cv2.INTER_CUBIC)
The coordinates of the bounding box are selected using the “poke” method. On the left, a small margin is taken, because the time in the match sometimes exceeds the mark of 100 minutes, in which case the clock will 100:00.
Brief overview of Tesseract, EasyOCR and TrOCR
The reader will detect time in the previous picture with the naked eye. 3:14. In addition, the task of optical character recognition is quite popular, it occurs when working with documents or, for example, license plates of cars. This suggests that there must be an open source model that works well out of the box.
Tesseract
The first thing that turned up in a Google search was its own project, according to Wikipedia, with a rather fascinating history.
Tesseract is a free OCR computer program developed by Hewlett-Packard from the mid-1980s to the mid-1990s and then shelved for 10 years. In August 2006, Google bought it and opened the source code under the Apache 2.0 license for further development.
Let’s execute the command.
tesseract \
<file_path> \
stdout \
--oem 1 \
--psm 7 \
-c tessedit_char_whitelist=0123456789
> 214As a result, 214 were recognized. Not bad for the first attempt, but not enough. On some similar images, the text is not recognized at all. Simple transformations by forces OpenCV did not help, and even if they did, my soul would still not be calm. The problem is most likely due to the fact that the model is used LSTMtrained back in 2019.
EasyOCR
The next thing that came to hand – EasyOCRwhich consists of Detector and Recognizer. The first is responsible for detecting texts in the picture, the second for recognition. To begin with, without fear, without respect, I tried to feed the entire frame, because the library from the box returns not only recognized characters, but also bounding boxes.
import easyocr
image = cv2.imread('youtube/frames/ukbICbM4RR0__033.bmp')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
reader = easyocr.Reader(['en'])
result = reader.readtext(image)
for (bbox, text, prob) in result:
(tl, tr, br, bl) = bbox
tl = (int(tl[0]), int(tl[1]))
tr = (int(tr[0]), int(tr[1]))
br = (int(br[0]), int(br[1]))
bl = (int(bl[0]), int(bl[1]))
cv2.rectangle(image, tl, br, (0, 255, 0), 2)
cv2.putText(image, text, (tl[0], tl[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (255, 0, 0), 2)
plt.rcParams['figure.figsize'] = (16, 16)
plt.imshow(image)
Indeed, many strings were detected and recognized. But the model missed the watch we were interested in. Moreover, if you look at the bottom of the picture, you can see that the name of the character DAWNBREAKER is not fully highlighted and is recognized as AWNBRIAKER.
I decided to give the models a cropped image as input, but the first time she did not recognize anything. You can get around the problem by leaving some space around the text.

The nuance is that the colon was recognized as 8, and as a result, the model issued 3814. Again a miss. On other frames, there was a problem that the model completely ignored the characters to the left of the colon.
The repository has a diagram of the algorithm.
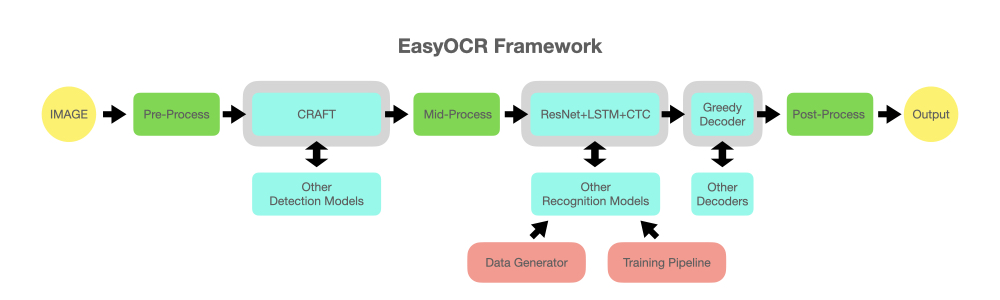
The key actors are ResNet and LSTM – all the same architecture from the “pre-transformer” era.
Also in the repository there is a script for training the model, but I’m not good at CV I was too lazy to mess around.
TrOCR
Finally I stumbled upon TrOCR. This library is not able to detect text in the picture, it can only recognize it. But that’s enough for us. The architecture looks like this:
Visual Transformer (ViT)as an encoder for image manipulation.RoBERTaas a text decoder.
Below is the diagram from the article. You need to read it from the right-bottom corner.

Explanation from the article about the decoder.
When loading the RoBERTa models to the decoders, the structures do not exactly match. For example, the encoder-decoder attention layers are absent in the RoBERTa models. To address this, we initialize the decoders with the RoBERTa models and the absent layers are randomly initialized.
Let’s execute the code.
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
model_version = "microsoft/trocr-base-printed"
processor = TrOCRProcessor.from_pretrained(model_version)
model = VisionEncoderDecoderModel.from_pretrained(model_version)
pixel_values = processor(image, return_tensors="pt").pixel_values
generated_ids = model.generate(pixel_values)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(generated_text)
> '3.14'Hurrah Hurrah! Model recognized 3.14. Practice has shown that in all frames a dot is recognized as a separator, not a colon. In some situations, the delimiter is not recognized at all. But we were lucky, in Dota 2 the time on the clock is always displayed in the format mm:ssso the problem can be solved by converting to timestamp.
def convert_to_timestamp(text):
sign = -1 if text.startswith('-') else 1
digits="".join([c for c in text if c.isdigit()])
seconds = digits[-2:]
seconds = int(seconds)
minutes = digits[:-2]
minutes = int(minutes)
timestamp = sign * (minutes * 60 + seconds)
return timestampconclusions
We learned how to download videos with highlights cuts from YouTube, sample frames and recognize the time on them. We also studied several libraries for character recognition in images. Specifically, in our example, transformers rule the ball and work out of the box without additional training and complex transformations of the input image.
In the next part, I plan to shoot sparrows with a cannon and use BERT to match video titles with records in the database in order to match frames and events from Dota 2 text replays.
I invite everyone who cares to comment.





