Parsing Markdown and LaTeX in the Grazie Chrome Plugin
You may already be using Grazie – plugin for the development environment Intellij IDEA, which checks natural languages for grammar, punctuation and other types of errors. The project team is currently working on a plugin for Chrome that will do the same, but in the browser. With some of the tasks they are assisted by interns – students of specialized programs from different universities. For example, Olga Shimanskaya is a third year undergraduate student “Modern programming»At St. Petersburg State University and in practice, a code for the Grazie Chrome Plugin. During the spring semester, Olya implemented parsing of markup languages (LaTeX and Markdown) into plain text and tried to approach the task of highlighting the syntax of the selected language in the browser. What she did and what didn’t, read under the cut.
A few words about myself
Hello everyone! My name is Olya Shimanskaya, and I am a 3rd year student of the program “Modern programming“At St. Petersburg State University. I entered here because of the small enrollment (only 30 people) and the high level of training. In the latter, I was sure, tk. the program was founded by some of the teachers from AU in 2018. Now my course is the oldest, and I really like it here.
I am interested in two areas: web development and machine learning. Before Grazie, I already had web development experience on a summer internship at Google and on a previous university project from the HSE LAMBDA laboratory. In the spring semester, we were offered many different projects, and I decided to qualify for Grazie: I was interested in the idea of the project, I was offered interesting and new problems, and I liked the team itself.
What is Grazie Chrome Plugin
Initially, Grazie is a plugin for the Intellij IDEA development environment. It checks natural languages for grammar, punctuation and other types of errors. Now the Grazie team is making a plugin for Chrome. “But why?” You ask. – “After all, there are Grammarly and other analogues.” The difference between Grazie is that it is initially targeted at programmers and IT terminology, while Grammarly marks specialized terms as errors. Also, developers use markup languages: Markdown, LaTeX, etc. – when writing documentation, articles and design documents, which also need to be correctly processed. With all this, the Grazie Chrome Plugin will help.
Note: At the moment, the Chrome plugin is only available to JetBrains employees, but I can tell you in confidence that it is awesome.
What did I do
I have been doing this project for a semester. I needed to figure out how:
-
Implement markup parsing into plain text and add index mapping from natural text to source text.
-
Determine the markup language and select the appropriate parser.
-
Support syntax highlighting for the selected language in the editor.
The whole project is written in TypeScript, uses the Webpack builder and the ESlint static analyzer.
While working on the project, I had weekly meetings with mentors, code review and chat for questions. They helped me to understand the code of the project and offered / supplemented ways to solve the tasks.
Parsing markup language
I started my work with a Markdown parser. For this I found a wonderful family of libraries and tools from unified. Of course, Markdown is a very popular markup language, and my bosses didn’t want me to write a bicycle. And the choice of libraries from npm was huge.
I settled on these libraries for the following reasons:
-
Popularity remark-parse – 5 million downloads per week.
-
This parser makes an AST and writes indexes in the text for each node (start and end positions). It was necessary for indexing from the final text to the original one.
-
A rich set of methods for traversing a tree.
I managed to figure out the project itself and implement this parser in two weeks.
LaTeX parser
Then I was offered several options for tasks: a LaTeX parser, a markup language detector, or add highlighting for Markdown. I decided to use a LaTeX parser because it would quickly add the Grazie Plugin the ability to check texts in Overleaf / Papeeria, which is what most users of these services need. For example, Grammarly, as far as I know, basically does not start checking in the Overleaf editor.
Initially, I thought that I could quickly complete this task and start implementing highlighting for Markdown, more complex and therefore interesting. But the implementation of the parser for LaTeX turned out to be more complicated, because LaTeX does not have context-free grammar. For example, here nice explanation with an example that the grammar is Turing complete and not at least context sensitive). In this article you can read more about these grammars and what hierarchy they form. This is a problem, since most of the context-sensitive grammars cannot be parsed in guaranteed polynomial time (the problem of decidability, that is, whether a string belongs to a language, is PSPACE-complete for KZ languages). Many parsers make the assumption that it is context free, and write tokenizers to implement the highlighting. Parser generators also assume that the input grammar will be context free. Of course, our task did not require a full-fledged parser, it was enough just to learn how to extract natural text from LaTeX and check it for grammatical, punctuation and other types of errors.
I used Tree-sitter, which the team lead advised for Markdown. Tree-sitter for a file with grammar (in .js format) generates an incremental (!) Parser in C. Also, a good grammar for LaTeX was found on the github for it, which I slightly modified: brought the vertices in AST with text to one type, removed some shortcomings of that grammar – for example, she parsed the text not in pieces (sentences / paragraphs), but in words, and she also did not have the support of some commands. The result is a fast and well-functioning parser. But, unfortunately, then we had to look for a new parser generator, because we ran into a problem.
… and what difficulties I had with him
As I already wrote, Tree-sitter generates a parser in C. For use in JavaScript, it has a binder that generates a .wasm file, and it can already be run in the browser. This was where the biggest problem lay: the managers and I did not know that almost all popular sites prohibit the launch of such files, because it is dangerous (Google CSP forbids eval and WASM files can be used for malicious purposes).
I had three options for how to deal with this problem:
-
Make a security hole by allowing this file to run for our plugin. But in this case, Google will check each plugin update for safety much longer due to the presence of the .wasm file.
-
Run it on the server, but this would greatly increase the parsing time, since it would have to spend time serializing / deserializing the AST and sending / receiving data.
-
Write a new parser.
New LaTeX parser!
I chose the latter option and rewrote the grammar from .js to .g4 for ANTLR4. It generates a lexer, parser and visitor in JS, and using antlr4ts you can generate all this in TypeScript. The problem was that one page of latex was processed for about 700 ms, and after simplifying the grammar, it turned out to be accelerated by only 2 times. With such a processing speed, the site page froze after each entered character.

As a result, it was decided to abandon writing a parser and building an AST. Instead, it would be sufficient to remove syntactic constructs using regular expressions and thus obtain natural text. The only subtlety is remembering to leave the text contained in some commands as an argument, such as “Some title” in title {Some title} (Other examples of such commands: text, author, date).
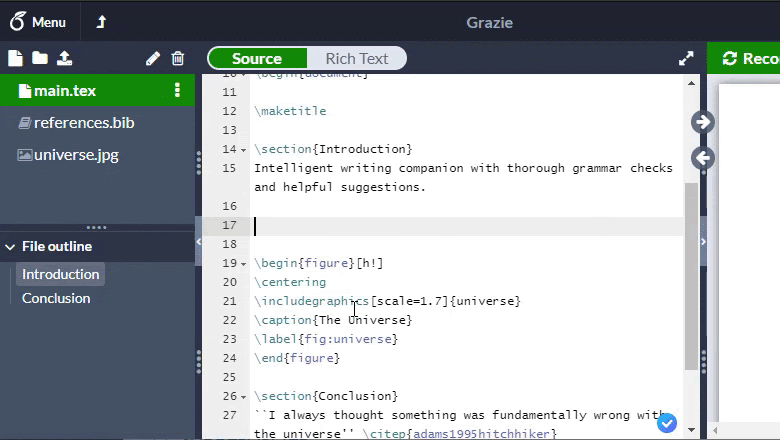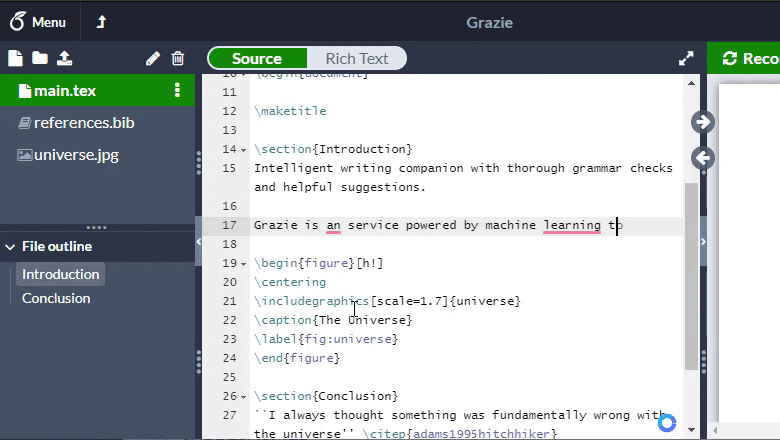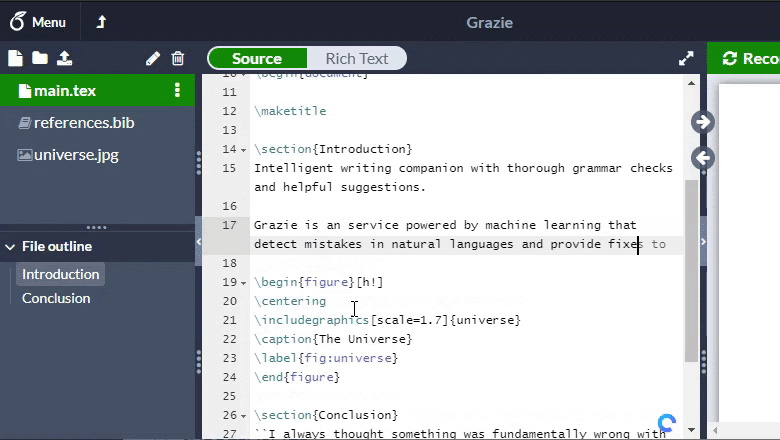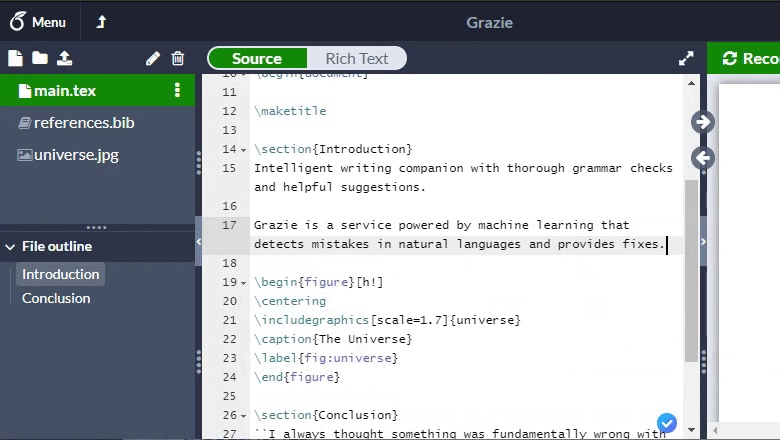
Thanks to this, it turned out to achieve processing in 5 ms per page:
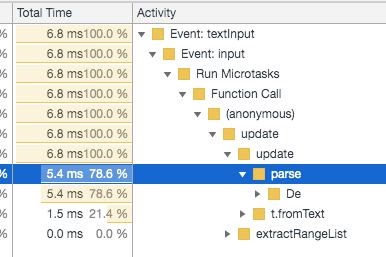
Browser syntax highlighting
In this task, we are faced with the following problems:
one. Changing the DOM tree of a site is bad / difficult / incomprehensible…
Why? Let’s say we want to highlight some kind of error in the editor using the background-color CSS property. We could change the content of the editor by wrapping the desired piece of text in a and adding the styles we need. But in this way we will affect the internal state of the element and now, for example, the copied text will contain the styles we have created. (I don’t know about you, but it pisses me off when you copy text from some site, and its background is copied with it)
Also, in the case of textarea and input, it will not be possible to manipulate the state, since it is encapsulated with shadow-root…
You can solve the problem of highlighting text by placing a div in the form of a rectangle above it and updating / deleting it when the content of the editor changes.
2. We want to change the color, slope, thickness of the text.
The idea was to look at mix-blend-mode and understand if it can be used to somehow change the color of the text. The property is very interesting and useful, but if we want to change the color of the text, then, firstly, it must be applied to the element in which it is located. Second, you cannot achieve arbitrary text colors. For example, if the text is black, then we can get the maximum shades of gray.
Another, more hardcore option, is to make this div the background color of the editor and write a similar piece of text in it. A definite plus – you can change its color. Cons – everything else. Every time you change the text, you need to update everything: take into account line breaks, make sure that our text in the div matches the style with the present. Also, it will not be so easy to make the font italic or give it a different weight, since the width of the resulting line will be different.
As a result, we came to the conclusion that it will not be possible to solve this problem with a simple HTML element and CSS style. There are two options left: canvas and CSS Paint… With their help, you can draw text pixel by pixel. For example, make a canvas in the form of a rectangle, place it above the desired text and change all the pixels of the text color in it to a different color. It is not yet very clear if this will work fast enough and if it will work at all. Apparently, the next intern has to find out …
results
As a result, I managed to add Markdown and LaTeX support to the plugin. Unfortunately, due to problems with the LaTeX parser, I have almost no time left for the last and most interesting syntax highlighting task, so I cannot say that I am happy with the result. But it’s great that I managed to do something useful and necessary for users.




