One-eyed depth gauge
Recently, there was an interesting article from FaceBook about how you can do good 3D from monocular cameras. The article is not very applicable in practice. But the picture quality is mesmerizing:

After looking at this, I decided to make a short story about what is going on in the article, where modern technologies have come, and what can be expected from them in practice.
Let’s start with the basics. There are several ways to shoot 3D:
Active 3D camera (lidar, projection, TOF). We radiate, we measure.
Stereo camera. We estimate the depth from geometry.
Monocular. We use either experience or camera shift to estimate depth.
In this article, we will take apart the monocular. What is its difficulty? Yes, here:

This picture describes the main problem very well. Even a person cannot estimate the depth from one angle. Something can, but the accuracy will not be very good + a lot of errors are possible.
How do they deal with this? The camera should move and the scene should not change. The algorithms that can assemble this image are called “SLAM”. The logic there is more or less the same (I describe it roughly):
In the first frame, select a set of features and put them in a common bag.
On each new frame, select the features, compare them with the features from the bag.
Having found the intersecting ones, you can estimate the current shift relative to other frames, and for all features from the bag, you can estimate the position
Here is an example of how it works from the distant 2014 (but in general it was much earlier):
The algorithms have one funny bug. You cannot know the absolute distances in the resulting scene. Only relative.
But this is not difficult to fix by measuring at least one object.
Good SLAM algorithms appeared ten years ago. You can now find them in AR Core or ARKitthat are available on almost every phone. This is how it would look right out of the box without any lidars:
The same algorithms are used in:
3D restoration algorithms based on a series of frames (photogrammetry)
Augmented reality algorithms for video editing
Drone orientation algorithms
And so on and so forth …
Of the best available OpenSource algorithms of this kind, there are now COLMAP… It’s conveniently packaged, and many researchers use it to create a basic solution.
But what are the problems with such algorithms?
All SLAM algorithms do not provide sufficient 3D density:


How do they deal with this?
There are many approaches. Previously, there were analytical, and now more popular – through neural networks. Actually, we will talk about two or three of the most popular and interesting ones.
We will talk about the most popular ones. Why not the “most accurate” ones? This is an interesting question. If we say “the most accurate”, then we must, for example, formalize on which dataset we compare the accuracy. Such datasets lot…
But here’s a serious minus – they are all specific. And often networks with good accuracy on such datasets work only on them. A good example is KITTY:
Networks that are optimized and well trained on it will not work very well on other data.
At the same time, 3D restoration is often not a simple construct of a plan to “check the depth on the dataset”, but something more complex, such as “check the accuracy of object restoration”, or “evaluate the accuracy over the entire video sequence”. And here already there will be few datasets, it is difficult to benchmark them.
If you look at some subtask of depth estimation – Depth Estimation, then for each “competition” there will be only one or two works.
So there is no point in talking about the most accurate. And I will talk, in my opinion, about the “most interesting and useful”, which shows different approaches.
MiDaS
Let’s start with a wonderful MiDaS… It came out a year ago, and was able to encapsulate a huge variety of ideas:
We were able to simultaneously train on many datasets with heterogeneous data. On stereo films, on data from depth sensors, on terrain scans, etc.
Trained fundamentally different model outputs to predict depth + different mixing methods to get an optimal estimate.
Were able to make this model fast enough
In addition, MiDaS is available out of the box on different platforms:
And this and that can be started in ten minutes. And the result? As a first approximation, something like this:
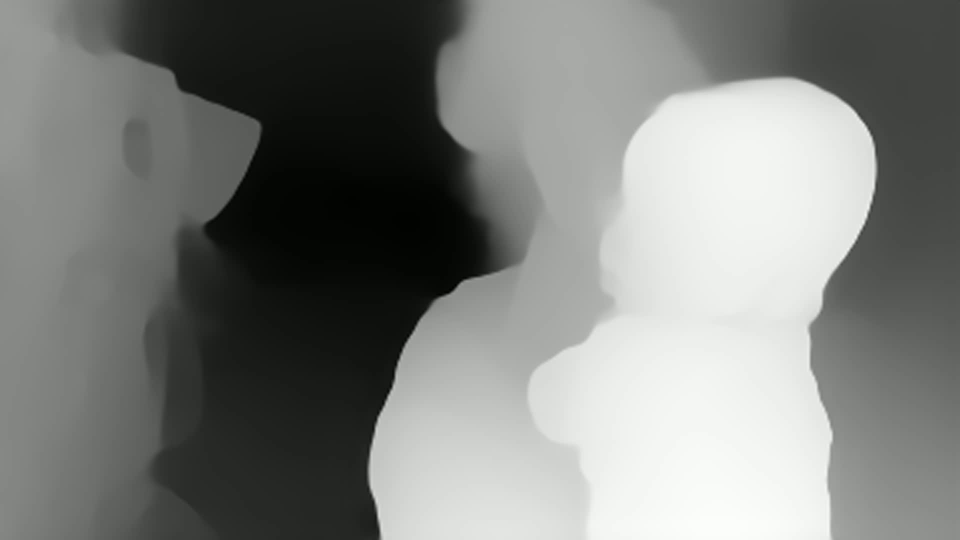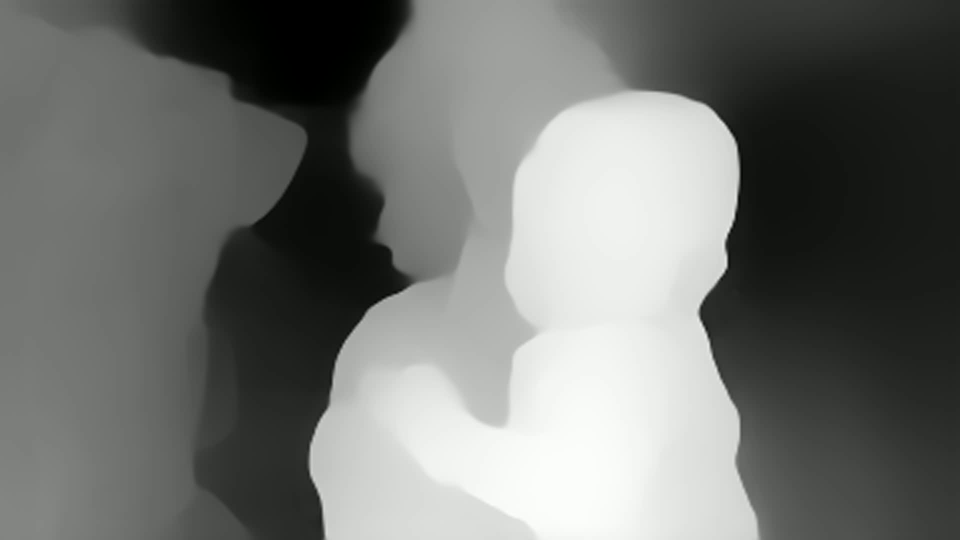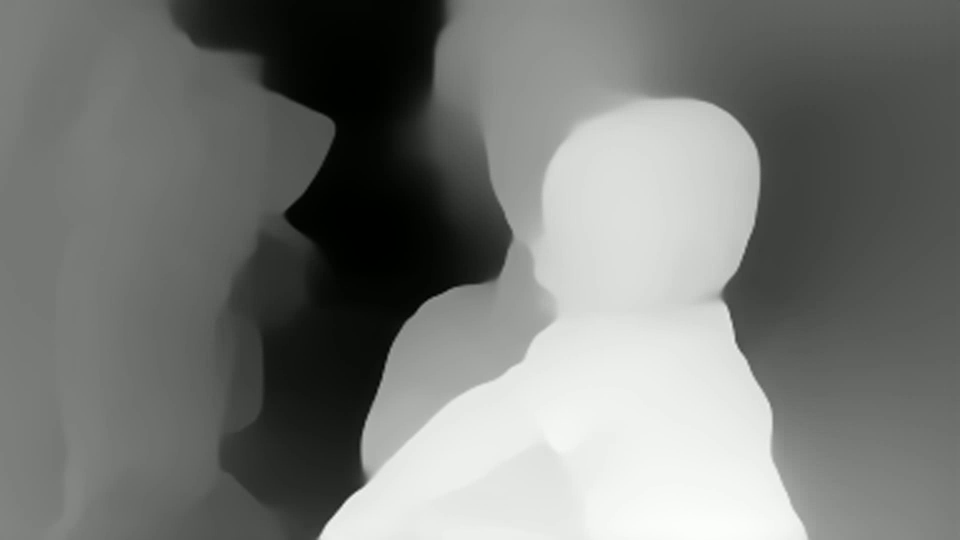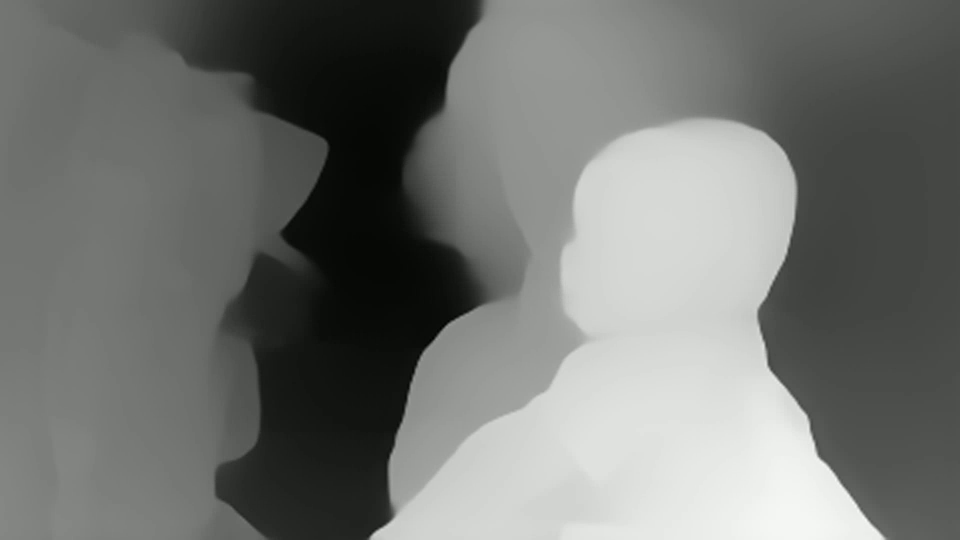
It can be seen that there is a depth estimate at each point. But you can immediately see that:
Depth instability is visible from frame to frame
No absolute size values (which is typical for monocular tasks)
Depth is handled quite well, including for objects with a similar background
But, naturally, such things cannot be trusted unambiguously:

Full scan
It is possible to eliminate jitter during a frame by taking into account adjacent frames and normalizing at their expense. And here the previously mentioned SLAM algorithms come to the rescue, with their help they construct a profile of the camera’s movement, link each frame to the general plan.
There are several algorithms that do this. for example Atlas and DELTAS

These approaches allow you to port the entire scan to TSDF space, and build a complete scan. The approaches are somewhat different. The first one builds a depth estimate for the entire scene using a bag of points:
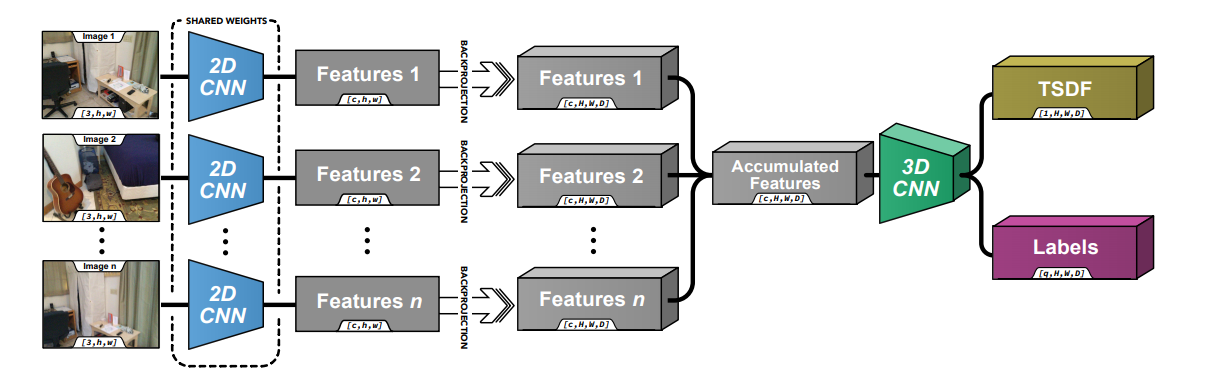
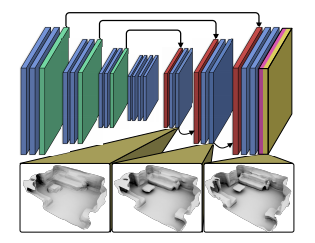
The second is about the same, but a little more complicated:
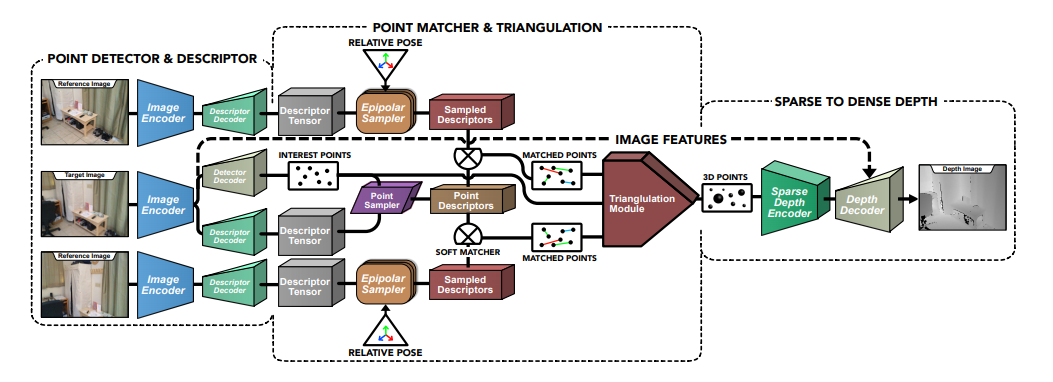
There are slightly more tricky approaches where the neural network estimates the depth as Midas and projects directly into the TSDF.
What is the accuracy of such methods? Of course, much less than any equipment equipped with a normal 3D scanner. For example, another scanner on the iPhone’s lidar:
Consistent Video Depth Estimation
Can you do more with a monocular camera? Yes, you can. But for this we need to go towards algorithms that estimate the depth by a series of frames in a sequence. An example of such an algorithm would be “Consistent Video Depth Estimation”.
Its peculiarity is an interesting approach, when two images are taken from a sequence, for which the shift is estimated through the previously mentioned SLAM. After that, these two images serve as an input for training the model for the current video:
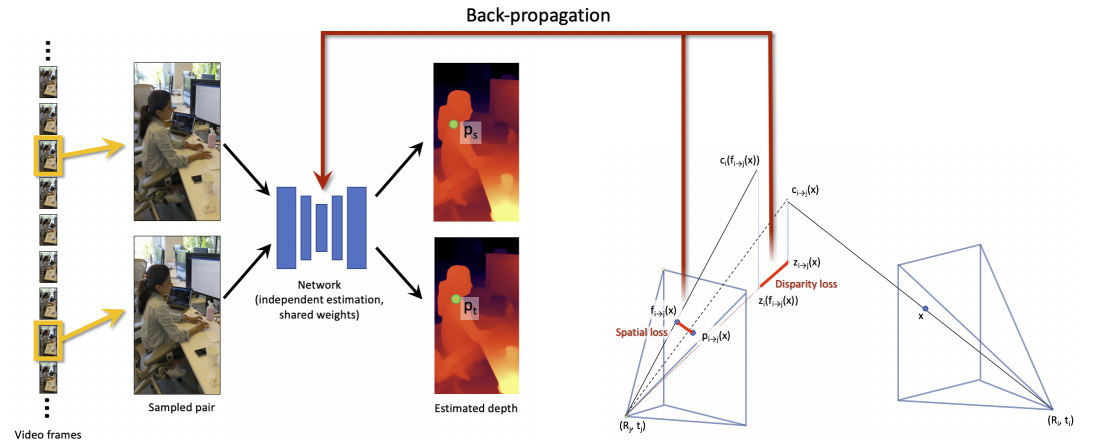
Yes, a separate model is trained (retrained) for each video, and the main disadvantage of this approach is its time. The calculation takes 4-5 hours for a 10-second video. But the result is amazing:

Why am I showing a video of examples here? It’s trite. Because to run this structure, even if there is colab on my video I could not.
But at the moment, such a thing shows State-Of-Art in depth recognition in video. And more examples can be found here…
In video format
About the same topic a few days ago I made a video on my channel. If it is more convenient for you to perceive information by ear, then it may be better to look there:
Conclusion
In general, in my opinion, monocular depth is not needed for serious tasks. And in the future, most likely, wherever a good depth is needed, it will be easier to use some kind of lidar, since the accuracy increases, and the price falls. Both lidars and stereo cameras use the same neural networks with might and main. Only in lidars and stereo cameras there is an estimate of the real depth in one frame – which makes them a priori more accurate.
But this does not negate the fact that today Monocular Depth is already used in dozens of applications where it is more convenient. And, perhaps, in the future, due to improved quality, it will be used even more often.
ps
Lately I have been doing a lot of small articles / videos. But since this is not a habr format, I publish them on my channel (cart, VK). On Habré, I usually publish when the story becomes more self-contained, sometimes you need 2-3 different mini-stories on neighboring topics.





