Monitoring your infrastructure with Grafana, InfluxDB and CollectD
For companies that need to manage data and applications on more than one server, infrastructure is paramount.
For every company, a significant part of the workflow is monitoring infrastructure nodes, especially in the absence of direct access to resolve emerging problems. Moreover, heavy use of some resources can be an indicator of infrastructure failures and overloads. However, monitoring can be used not only for prevention, but also for assessing the possible consequences of using new software in production. There are several ready-to-use solutions currently on the market for tracking resource consumption, but they nevertheless pose two key problems: the high cost of installation and configuration and the security issues associated with third-party software.
The first issue is the issue of price: the cost can range from ten euros (consumer rates) to several thousand (corporate rates) per month, depending on the number of hosts to be monitored. For example, let’s say I want to monitor three nodes for one year. With a price of 10 euros per month, I will spend 120 euros, while a small company will have to fork out for ten to twenty thousand, which will turn out to be a financially untenable decision and will simply undermine the entire budget.
The second problem is third-party software. Given that, for analysis, user data – whether an individual or a company – must be processed by a third party, the question arises: how does the third party collect the data and present it to the user? Usually, for this, a special application is installed on the node, through which monitoring is carried out, but often such applications have time to become outdated or turn out to be incompatible with the client’s operating system. Researchers’ experience in the field of information security sheds light on the problems in working with “proprietary software“. Would you trust such software? Me not.
I have my nodes as for Torand for some cryptocurrenciesso I prefer the free, open source, easily customizable alternatives for monitoring. In this post, we’ll look at three such tools: Grafana, InfluxBD, and CollectD.

Monitoring
To effectively analyze each metric of our infrastructure, we need an application that can pick up statistics from the devices of interest to us. In this regard, comes to our aid CollectD: this daemon groups and collects (“collects”, hence the name) all parameters that can be stored on disk or transmitted over the network.
The data will then be transferred to the instance InfluxDB: This is a time series database (TSBD) that associates data with the time (UNIX encoded timestamp) at which the server received it. Thus, the data sent by CollectD will arrive as a sequence of events.
Finally, we will use Grafana: This program will connect to InfluxDB and display the data on user-friendly colorful dashboards. Thanks to all kinds of graphs and histograms, we will be able to track the data of the CPU, RAM, and so on in real time.

InfluxDB

Let’s start with InfluxDB. freely distributed TSBD for storing data as a sequence of events. This one developed on Go the database will become the heart of our monitoring “system”.
Whenever data comes in, it is bound by default UNIX label… The flexibility of this approach frees the user from having to store the variable “time”, which is otherwise rather complicated. Let’s imagine that we have several devices located on different continents. How do we handle the “time” variable? Are we going to tie all data to the time by Greenwich, or will we give each node its own time zone? If the data is stored in different time zones, how can we display it correctly on the charts? As you can see, problems arise one after another.
Since InfluxDB keeps track of time and automatically tags each data arrival, it can synchronously write data to a specific database. That is why InfluxDB is often presented as a timeline: writing data does not affect the performance of the database (which sometimes happens with MySQL), since writing is just adding a specific event to the timeline. Therefore, the name of the program comes from the perception of time as an endless and unlimited “stream”.
Installation and configuration
Another advantage of InfluxDB is ease of installation and provided by the project community that supports it widely, extensive documentation… InfluxDB has two types of interface: command line (a handy tool for developers, but poorly prepared for working with large amounts of data) and HTTP API for direct interaction with the database.
You can download InfluxDB not only from the official site, but also through the package management system (we will demonstrate this through Debian). In addition, it is recommended to check the packages via GPG before installing, so below we import the keys of the InfluxDB package:
root@node#~: curl -sL https://repos.influxdata.com/influxdb.key | sudo apt-key add -
root@node#~: source /etc/os-release
root@node#~: echo "deb https://repos.influxdata.com/debian $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/influxdb.listFinally, we’ll update and install InfluxDB:
root@node#~: apt-get update
root@node#~: apt-get install influxdbTo run we will use systemctl:
root@node#~: service start influxdb To prevent someone with nefarious intentions logging in to us, we will create a user called “administrator”. You can interact with the database using the SQL-like query language available in InfluxDB “InfluxQL“. To create a new user, we will run the request create user…
root@node#~: influx
Connected to http://localhost:8086
InfluxDB shell version: x.y.z
>
> CREATE USER admin WITH PASSWORD 'MYPASSISCOOL' WITH ALL PRIVILEGESIn the same CLI interface, we will create a database “metrics”, in which we will store our metrics.
> CREATE DATABASE metricsThen we’ll set up the InfluxBD configuration (/etc/influxdb/influxdb.conf) so that the interface is opened through the port 24589 (UDP) with direct connection to “metrics” database for CollectD support. We will also need to download the file types.db and place it at /usr/share/collectd/ (or in any other folder) to correctly define the data that CollectD transfers in native format…
root@node#~: nano /etc/influxdb/influxdb.conf
[Collectd]
enabled = true
bind-address = ":24589"
database = "metrics"
typesdb = "/usr/share/collectd/types.db"You can read more about CollectD in configuration in documentation…
CollectD

CollectD in our monitoring infrastructure will act as a data aggregator that simplifies data transfer to InfluxDB. By definition, CollectD collects metrics from CPU, RAM, hard drives, network interfaces, processes … The potential of this program is limitless, especially when you consider a wide selection as already available pluginsand the set planned…
As you can see, installing CollectD is simple:
root@node#~: apt-get install collectd collectd-utilsLet’s illustrate how CollectD works with a simplified example. Let’s say I want to know the number of processes on my node. To check this, CollectD will make an API call to find out the number of processes per unit of time (5000 milliseconds by definition) and nothing more. As soon as the aggregator receives the data, it will transfer it to InfluxDB for configuration through a module (called “Network”), which we will need to configure.
Open the file with our editor /etc/collectd.conf, scroll to section Network and edit it as shown below. Be sure to specify the IP on which the InfluxDB interface is located (INFLUXDB_IP).
root@node#~: nano /etc/collectd.conf
...
ReportStats true
...
I suggest changing the hostname in the configuration file that is forwarded to InfluxDB (in our infrastructure, this is a “centralized” database since it is located on the same node). Thus, we will not receive unnecessary data and the risk of data being overwritten by other nodes will disappear.

Grafana

One graph is worth a thousand images
Considering the paraphrased quote, observing infrastructure metrics in real time through graphs and tables allows us to act efficiently and in a timely manner. We’ll use Grafana to create and customize the dashboard for our graphs and tables.
Grafana is a freeware graphical metrics tool, compatible with a wide range of databases (including InfluxDB), in which the user can create alerts when a piece of data meets a specific condition. For example, if your processor is peaking, you might receive an alert in Slack, Mattermost, email, and so on. Moreover, I configured my alerts to actively monitor every case when someone “enters” my infrastructure.
Grafana does not require any special settings: as we noted earlier, InfluxDB “scans” the “time” variable. The integration itself is very simple: we’ll start by importing the public key to add a package with official site of Grafana (it depends on your operating system):
root@node#~: wget -q -O - https://packages.grafana.com/gpg.key | sudo apt-key add -
root@node#~: echo "deb https://packages.grafana.com/oss/deb stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list
root@node#~: apt-get update && apt-get install grafanaThen let’s run it through systemctl:
root@node#~: systemctl start grafana-webNow when we navigate to the localhost: 3000 page in the browser, we should see the Grafana login interface. By definition, you can log in via login admin and password admin (after the first login, it is recommended to change the credentials).

Let’s go to the Sources section and add our Influx database there:


A small green rectangle is now visible under the New Dashboard label. Hover your cursor over it and select Add Panel and then Graph:

Now you can see the graph with test data. Click on the title of this diagram and click Edit. With Grafana, you can create smart queries: you do not need to know every field in the database, Grafana will offer them to you from a list of parameters suitable for analysis.
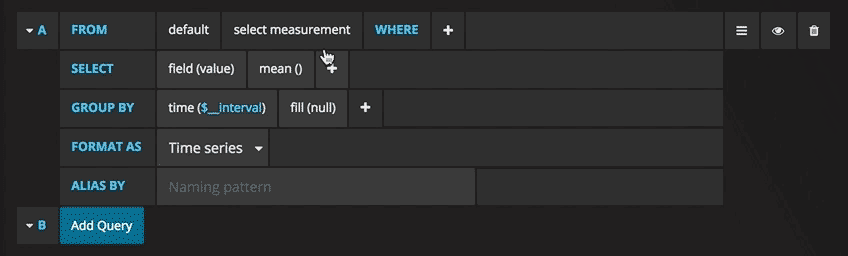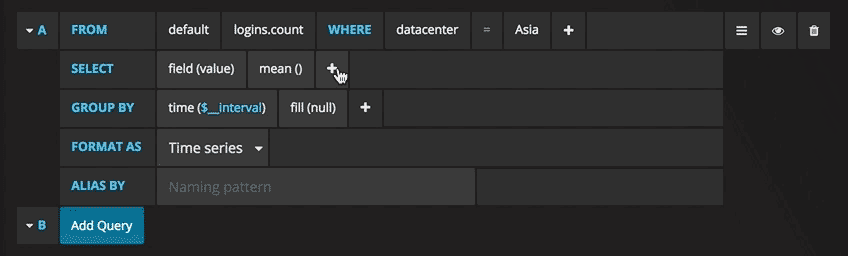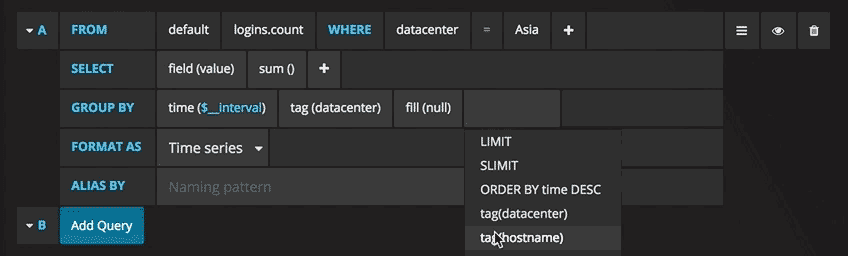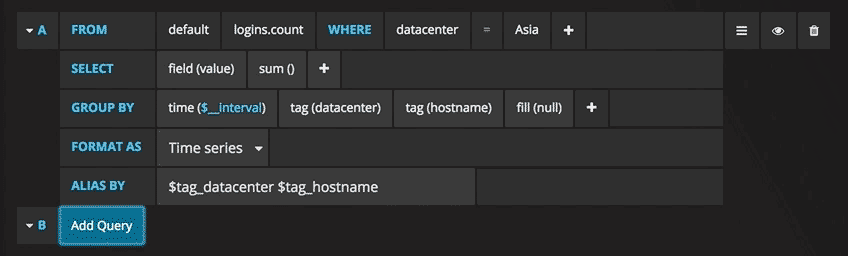
Writing queries has never been easier: just select the metric you are interested in and click Refresh. I also recommend dividing metrics by host to make it easier to isolate issues. If you are interested in other control panel ideas, you can visit the Grafana site for all sorts of examples for inspiration.
We noticed that Grafana is a very extensible tool, and it allows us to compare data that is very different in comparison to each other. There is not a single metric that cannot be obtained, so only your ingenuity limits you. Track your devices and get the most complete overview of your infrastructure in real time!