Meet WSE-2: 7nm processor with 850 thousand cores and 15 kW power consumption

Cerebras introduced its first processor two years ago, the size of which was equal to the size of a silicon wafer. Its area was 46,225 mm², dimensions – 220×220 mm, the number of transistors – 1.2 trillion. The first chip was named WSE (Wafer Scale Engine) and was manufactured according to the 16nm process technology.
As for the new chip, it is made according to the 7nm technical process. The area remains the same, but there are twice as many transistors – now 2.6 trillion. The number of cores has also more than doubled: 850 thousand instead of 400 thousand, as in the previous model. The processor is designed for data centers, computing tasks in the field of machine learning and artificial intelligence (AI).
Details of the creation and characteristics of the WSE-2
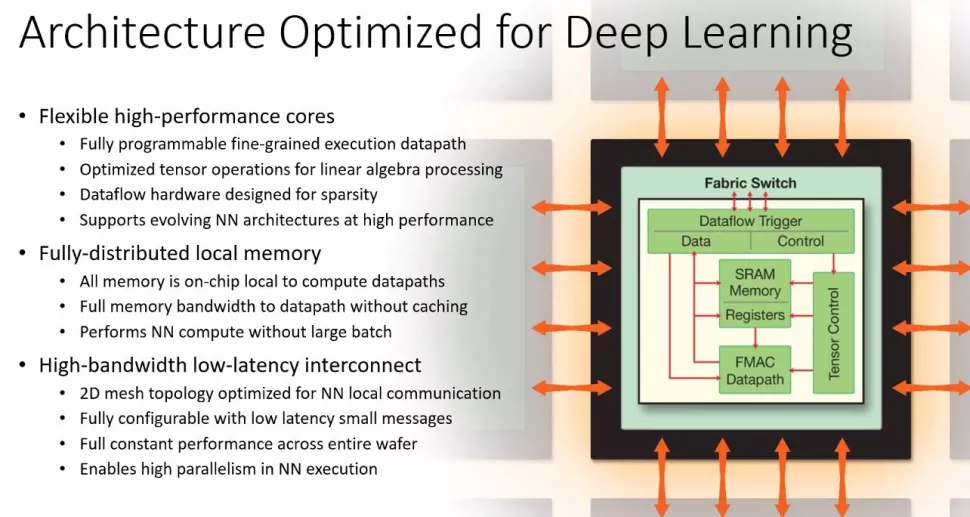
The chip has 40GB of internal SRAM – 22GB more than the previous model. The bandwidth is 20 PB / s. At the same time, the power consumption of the chip remained at the same level – 15 kW.

Note that this processor is not a concept, but quite a working system. Its creators achieve very high productivity by stitching dies onto a silicon wafer via a communication network. The total throughput eventually rises to 220 PB / s. The core frequency is from 2.5-3 GHz.
| Cerebras Wafer Scale Engine 2 | Cerebras Wafer Scale Engine | Nvidia A100 | |
| Process Node | TSMC 7nm | TSMC 16nm | TSMC 7nm N7 |
| AI Cores | 850,000 | 400,000 | 6.912 + 432 |
| Die Size | 46,255 mm2 | 46,255 mm2 | 826 mm2 |
| Transistors | 2.6 Trillion | 1.2 Trillion | 54 Billion |
| On-Chip SRAM Memory | 40 GB | 18 GB | 40 MB |
| Memory Bandwidth | 20 PB / s | 9 PB / s | 1,555 GB / s |
| Fabric Bandwidth | 220 Pb / s | 100 Pb / s | 600 GB / s |
| Power Consumption (System / Chip) | 20kW / 15kW | 20kW / 15kW | 250W (PCIe) / 400W (SXM) |
The chip itself is useless, but the company has specially developed a 15U system for it, which is sharpened exclusively for the characteristics of the WSE-2. The second generation system is almost indistinguishable from the first one. The first generation blocks were previously shipped to customers. One of them is installed at the Argonne National Laboratory of the US Department of Energy. She uses the first system for scientific purposes – for example, studying black holes, as well as for working with medical problems such as analyzing the causes of cancer. Another customer was Livermore National Laboratory.
The chip and the system for it will go on sale in the third quarter of 2021. The price is still unknown.
The company said the compiler is easily scalable, so there is no problem using the existing ecosystem of applications. WSE-2 understands standard PyTorch and TensorFlow code that can be easily modified using specialized software tools and APIs.
What is the uniqueness of such a processor?
It is in size. The fact is that it is very difficult to work with one large chip, the area of which is equal to the area of a silicon wafer. Typically, microcircuits are created on round silicon wafers with a diameter of 30.5 cm. 100 chips can be made from each.
But not all manufactured chips can be used, the rejection rate is quite high. The problem is in the chain etching process in silicon. It is so complex that it does not always pass without errors, and some circuits simply do not work as a result. Due to the fact that modern processors are small, the error rate is low. The larger the chip area, the more likely it is to get defects that will prevent the chip from being used normally.
Large processors have been tried before. For example, in 1980, ex-IBM employee Gene Amdahl founded Trilogy. It received as much as $ 230 million in investment, but in the end was never able to release the finished product, so it was closed in 1985.
But Cerebras seems to have succeeded. How she managed to achieve success is still unclear, but since the finished product is already used by customers, then everything is fine. The WSE is capable of training AI systems 100 to 1,000 times faster than existing hardware, the company said. This was achieved by filtering zero data with SLACs (Sparse Linear Algebra Cores). They are optimized for vector space computations. In addition, developers have been able to create sparsity harvesting to improve compute performance on sparse (zeros) workloads such as deep learning.






