Machine learning with Dask
Processing even a couple of gigabytes of data on a laptop can only be a daunting task if it doesn’t have a lot of RAM and good processing power.
Despite this, data scientists still have to find alternative solutions to this problem. There are options to set up Pandas to handle huge datasets, buy GPUs, or buy cloud computing power. In this article, we will look at how to use Dask for large datasets on the local computer.
Dask and Python
Dask is a flexible parallel computing library for Python. It works great with other open source projects such as NumPy, Pandas, and scikit-learn. Dask has a structure arrayswhich is equivalent to arrays in NumPy, dataframes in Dask are similar to dataframes in Pandas, and Dask-ML Is analogous to scikit-learn.
These similarities make it easy to integrate Dask into your work. The advantage of using Dask is that you can scale computations to multiple cores on your computer. So you get the opportunity to work with large amounts of data that do not fit in memory. You can also speed up calculations that usually take up a lot of space.
Dask DataFrame
When loading a large amount of data, Dask usually reads a sample of the data in order to recognize the data types. This most often leads to errors, since there can be different data types in the same column. It is recommended that you declare the types ahead of time to avoid errors. Dask can upload huge files by slicing them into blocks defined by parameter blocksize…
data_types ={'column1': str,'column2': float}
df = dd.read_csv(“data,csv”,dtype = data_types,blocksize=64000000 )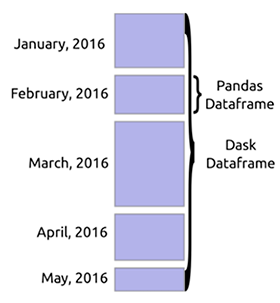
The commands in Dask DataFrame are similar to those in Pandas. For example, getting head and tail dataframe in the same way:
df.head()
df.tail()The functions in the DataFrame are lazy. That is, they are not calculated until the function is called compute…
df.isnull().sum().compute()Since the data is loaded piece by piece, some Pandas features such as sort_values() will fail. But you can use the function nlargest().
Clusters in Dask
Parallel computing is key to Dask because it allows you to read on multiple cores at the same time. Dask provides machine schedulerthat runs on one machine. It doesn’t scale. There is also distributed schedulerwhich allows you to scale to multiple machines.
Using dask.distributed requires client configuration. You will do this first thing if you intend to use dask.distributed in the analysis. It provides low latency, data locality, worker-to-worker communication, and is easy to configure.
from dask.distributed import Client
client = Client()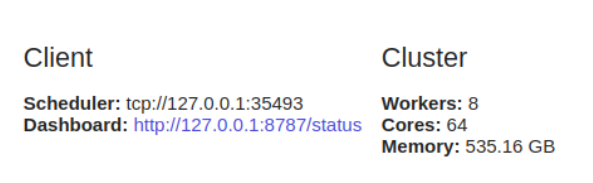
Use dask.distributed advantageous even on a single machine as it offers diagnostic functions via a dashboard.
If you don’t customize Clientthen by default you will use the machine scheduler for one machine. It will provide concurrency on a single computer using processes and threads.
Dask ML
Dask also allows for parallel model training and prediction. goal dask-ml – offer scalable machine learning. When you declare n_jobs = -1 в scikit-learn, you can run calculations in parallel. Dask uses this capability to enable you to do computations in a cluster. This can be done using the package joblibwhich allows parallelism and pipelining in Python. With Dask ML, you can use scikit-learn models and other libraries like XGboost.
A simple implementation would look like this.
First, import train_test_splitto split your data into training and test suites.
from dask_ml.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)Then import the model you want to use and instantiate it.
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(verbose=1)Then you need to import joblibto enable parallel computing.
import joblibThen start training and forecasting with the parallel backend.
from sklearn.externals.joblib import parallel_backend
with parallel_backend(‘dask’):
model.fit(X_train,y_train)
predictions = model.predict(X_test)Limits and memory usage
Individual tasks in Dask cannot run in parallel. Workers are Python processes that inherit the advantages and disadvantages of Python computation. In addition, when working in a distributed environment, care must be taken to ensure the security and privacy of your data.
Dask has a central scheduler that monitors data on worker nodes and in the cluster. It also manages the release of data from the cluster. When the task is completed, it will immediately remove it from memory to make room for other tasks. But if something is needed by a certain client, or is important for current calculations, it will be stored in memory.
Another limitation of Dask is that it doesn’t implement all of Pandas’ functionality. The Pandas interface is very large, so Dask doesn’t cover it completely. That is, performing some of these operations in Dask can be challenging. In addition, slow operations from Pandas will also be slow in Dask.
When you don’t need a Dask DataFrame
In the following situations, Dask may not be the right option for you:
- When Pandas has functions that you need, but Dask hasn’t implemented them.
- When your data fits perfectly into your computer’s memory.
- When your data is not presented in tabular form. If so, try dask.bag or disk.array…
Final thoughts
In this article, we looked at how you can use Dask to work distributedly with huge datasets on your local computer. We saw that we can use Dask as its syntax is already familiar to us. Also Dask can scale to thousands of cores.
We also saw that we can use it in machine learning for prediction and training. If you want to know more, check out these materials in documentation…

Read more:
- Two AI megatrends dominating the Gartner Hype Cycle 2020





