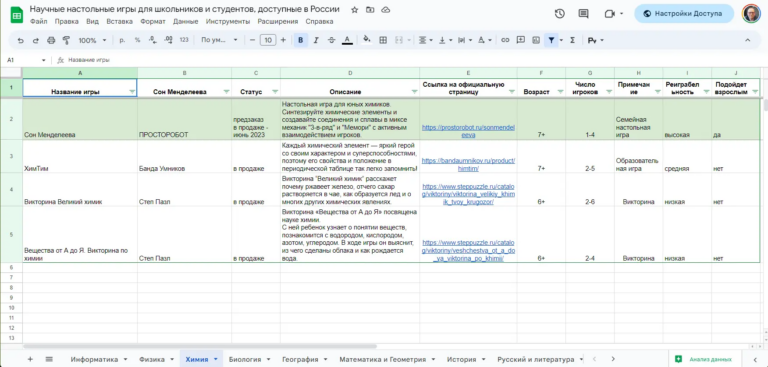
“Life” on PostgreSQL
The use of special tools for other purposes often causes negative feedback from professionals. However, solving meaningless but interesting tasks trains lateral thinking and allows you to explore the tool from different points of view in search of a suitable solution.
And further. Let’s be honest: always using SQL for its intended purpose is a green boredom. Consider the examples given in all the textbooks, starting with the same article by Codd? Suppliers and parts, employees and departments … And where is the pleasure, where is the fun? For me, one of the sources of inspiration is comparing procedural decisions with declarative ones.
I, excuse me, will not explain what is A life John Conway. I can only say that – turns out – using a cellular automaton Of life, it is possible to build a universal Turing machine. It seems to me that this is a grandiose fact.
So, is it possible to implement the game A life with one SQL statement?
Okay, let’s get started.
Our field will be a table with the coordinates of living cells, and not at all a two-dimensional array, as you might think in a rash mind. This view is more natural for SQL, it simplifies the code and allows you not to think about field boundaries. In addition, the speed of calculations (which, however, hardly worries us here) will depend only on the number of living cells, and not on the size of the field.
CREATE TABLE matrix (
rw integer,
cl integer,
val float
);
A simple example that effectively blows up a procedurally tuned brain is matrix multiplication. Let me remind you that the product of the matrix A (L × M) and the matrix B (M × N) is the matrix С (L × N), whose elements are ci, j = ∑k = 1 … M ai, k × bk, j…
The procedural algorithm uses a triple nested loop over i, j, k. A simple connection is enough for an SQL query:
SELECT a.rw, b.cl, sum(a.val * b.val)
FROM a
JOIN b ON a.cl = b.rw
GROUP BY a.rw, b.cl;
The request should be carefully examined and understood. Out of habit, it’s not even easy at all. There are no loops here: the query operates on sets of elements and their connection. There is no matrix dimension here. There is no need to store zero elements in the table here.
But after the brain explodes, the code is made obvious and no more complicated than the procedural one. This is an important point.
So the field:
CREATE TABLE cells(
x integer,
y integer
);
INSERT INTO cells VALUES
(0,2), (1,2), (2,2), (2,1), (1,0); -- glider
To count the neighbors, instead of turning the procedural loops, let’s move our “matrix” one cell in all eight directions and sum up the number of living cells in each position.
WITH shift(x,y) AS (
VALUES (0,1), (0,-1), (1,0), (-1,0), (1,1), (1,-1), (-1,1), (-1,-1)
),
neighbors(x,y,cnt) AS (
SELECT t.x, t.y, count(*)
FROM (
SELECT c.x + s.x, c.y + s.y
FROM cells c
CROSS JOIN shift s
) t(x,y)
GROUP BY t.x, t.y
)
SELECT * FROM neighbors;
Shifts can also be constructed with a query, but it probably won’t make it any easier.
Having neighbors, it remains to decide which cells should die and which ones should be born:
WITH shift(x,y) AS (
...
),
neighbors(x,y,cnt) AS (
...
),
generation(x,y,status) AS (
SELECT coalesce(n.x,c.x),
coalesce(n.y,c.y),
CASE
WHEN c.x IS NULL THEN 'NEW'
WHEN n.cnt IN (2,3) THEN 'STAY'
ELSE 'DIE'
END
FROM neighbors n
FULL JOIN cells c ON c.x = n.x AND c.y = n.y
WHERE (c.x IS NULL AND n.cnt = 3)
OR
(c.x IS NOT NULL)
)
SELECT * FROM generation;
Complete connection is necessary here so that, on the one hand, a new life can arise in an empty cell, and on the other, to destroy living cells “in the suburbs.” We have three conditions for getting into the sample: either the cell is empty and has exactly three neighbors (then it should come to life and receive the NEW status), or it is alive and has two or three neighbors (then it survives and receives the STAY status), or it is alive, but has less than two or more than three neighbors (then it is doomed to death and receives DIE status).
Now we need to update the playing field using information about the new generation of cells. This is where PostgreSQL’s capabilities come in handy: we’ll do everything we need to in the same SQL statement.
WITH shift(x,y) AS (
...
),
neighbors(x,y,cnt) AS (
...
),
generation(x,y,status) AS (
...
),
del AS (
DELETE FROM cells
WHERE (x,y) IN (
SELECT x, y FROM generation WHERE status="DIE"
)
),
ins AS (
INSERT INTO cells
SELECT x, y FROM generation WHERE status="NEW"
)
SELECT *
FROM generation
WHERE status IN ('STAY','NEW');
Actually, all the logic of the game is written!
It is already easy to attach to this algorithm the display of the result in the form of a two-dimensional matrix familiar to the eye. And, like the icing on the cake, you can end the query with the psql command watchso that generations follow each other on the screen every second.
Here is the entire query, with minimally digestible output. Copy, paste, and enjoy!
WITH shift(x,y) AS (
VALUES (0,1), (0,-1), (1,0), (-1,0), (1,1), (1,-1), (-1,1), (-1,-1)
),
neighbors(x,y,cnt) AS (
SELECT t.x, t.y, count(*)
FROM (
SELECT c.x + s.x, c.y + s.y
FROM cells c
CROSS JOIN shift s
) t(x,y)
GROUP BY t.x, t.y
),
generation(x,y,status) AS (
SELECT coalesce(n.x,c.x),
coalesce(n.y,c.y),
CASE
WHEN c.x IS NULL THEN 'NEW'
WHEN n.cnt IN (2,3) THEN 'STAY'
ELSE 'DIE'
END
FROM neighbors n
FULL JOIN cells c ON c.x = n.x AND c.y = n.y
WHERE (c.x IS NULL AND n.cnt = 3)
OR
(c.x IS NOT NULL)
),
del AS (
DELETE FROM cells
WHERE (x,y) IN (
SELECT x, y FROM generation WHERE status="DIE"
)
),
ins AS (
INSERT INTO cells
SELECT x, y FROM generation WHERE status="NEW"
),
dimensions(x1,x2,y1,y2) AS (
SELECT min(x), max(x), min(y), max(y)
FROM generation
WHERE status IN ('STAY','NEW')
)
SELECT string_agg(CASE WHEN g.x IS NULL THEN ' ' ELSE '*' END, '' ORDER BY cols.x)
FROM dimensions d
CROSS JOIN generate_series(d.x1,d.x2) cols(x)
CROSS JOIN generate_series(d.y1,d.y2) lines(y)
LEFT JOIN generation g ON g.x = cols.x AND g.y = lines.y AND g.status IN ('STAY','NEW')
GROUP BY lines.y
ORDER BY lines.y
watch 1