Interpretability in medicine
Coincidentally, I recently read an article Transparency of deep neural networks for medical image analysis and a post from the Reliable ML channel about interpretability. I have been working in the field of medicine for almost five years, and all this time this topic has constantly flashed somewhere in the orbit of attention.
What is interpretability, if the task of classifying the entire X-ray examination is being solved, is generally clear. Doctors do not trust systems that simply say “there is cancer somewhere in the picture,” which means that some methods are needed that will “explain” the final prediction. Quite a lot of them have been invented – various types of GradCAM, occlusion, LIME. Out of the box, many of them can be taken from the library Captum for Pytorch.
If you want to learn more about the organization of ML development processes, subscribe to our Telegram channel Cook ML

However, life shows that the quality of localization of clinically significant signs in these methods is, to put it mildly, unsatisfactory. At the same time, it is unlikely that anyone will seriously consider an AI system that does not solve the problem of localization – detection or segmentation. Yes, and really good metrics on pure classification can only be achieved if there are very large, clean datasets. At the moment we have four systems in production, one of them is detection, two are instance segmentation, and one more is semantic segmentation.
When the system is able to localize areas of interest and assign them a class (for example, a malignant tumor, a lymph node, and so on), the question of interpretability seems to disappear. Indeed, for several years we worked, remembering about interpretability only at internal meetups.
Why is interpretability necessary?
Last year, we decided that we were not Moscow alone, and we began to breed activities in other regions – both in state and commercial clinics. The sales process in 99% of cases includes testing the system on customer data. Someone only looks at aggregated results and metrics, but most chief physicians and medical directors like to visually evaluate the results of the system. In addition, since September 2022, the Moscow experiment has introduced a procedure clinical assessment. Doctors-experts monthly evaluate the results of the system on a randomly selected 80 studies. In general, the number of feedback and questions has increased significantly.
Here are some examples of questions and comments:
-
“Why did the AI highlight this area as a pathology, but not the next one? They look almost the same!”
-
“Why shadow summation and digitization artifacts are regarded as malignant formations?”
-
“Why is pathology singled out on one projectionsbut not on the other?
-
“Why is the area of potential pathology highlighted, but the overall assessment of the study is the norm”?
Such “jambs” cause bewilderment of doctors and significantly reduce the likelihood of a sale. What can be done?
-
Improve systems through additional training and architecture changes
-
Add different heuristics and hacks to avoid certain types of errors
-
Conduct educational work so that doctors better understand the sources of certain errors and the general essence of the work of AI systems
-
Add mechanisms for interpreting and explaining predictions to help answer those “whys”
I just want to analyze some of the ways of interpretation from the article from the first paragraph and give examples of use from our practice.
Ways of Interpretation
Clinical concepts
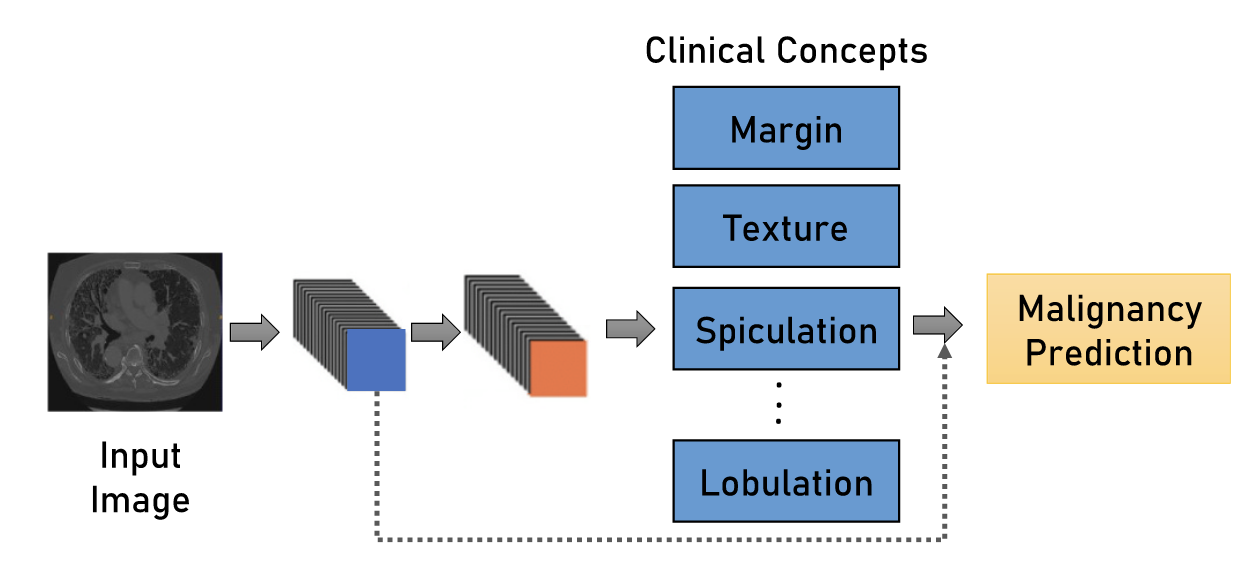
The essence of this method is quite simple, but at the same time attractive. Instead of directly predicting the RoI (Region-of-Interest) class using a grid, we will first determine its various properties related to texture, shape, density relative to the surrounding tissue, size. And already on the basis of these properties, we can, on the basis of rules or using a simple linear model, determine a specific type of object – for example, it is malignant or benign. It sounds extremely nice – for each prediction, we can explain to the doctor why it is that way. The method is, of course, not ideal:
-
Most likely, for the correct calculation of most features, very accurate segmentation of the RoI contour will be required.
-
Metrics can drop compared to direct classification
-
The model can simply skip the required RoI, and then questions will still arise.
-
Some clinical features are difficult to quantify
We use a similar idea to assign a total pathology risk in a study. Instead of directly solving the problem of binary classification (0 – normal, 1 – pathology) by pictures, we use the found objects, their probabilities, classes and sizes as features of a simple meta-model – for example, LightGBM.
concept attribution
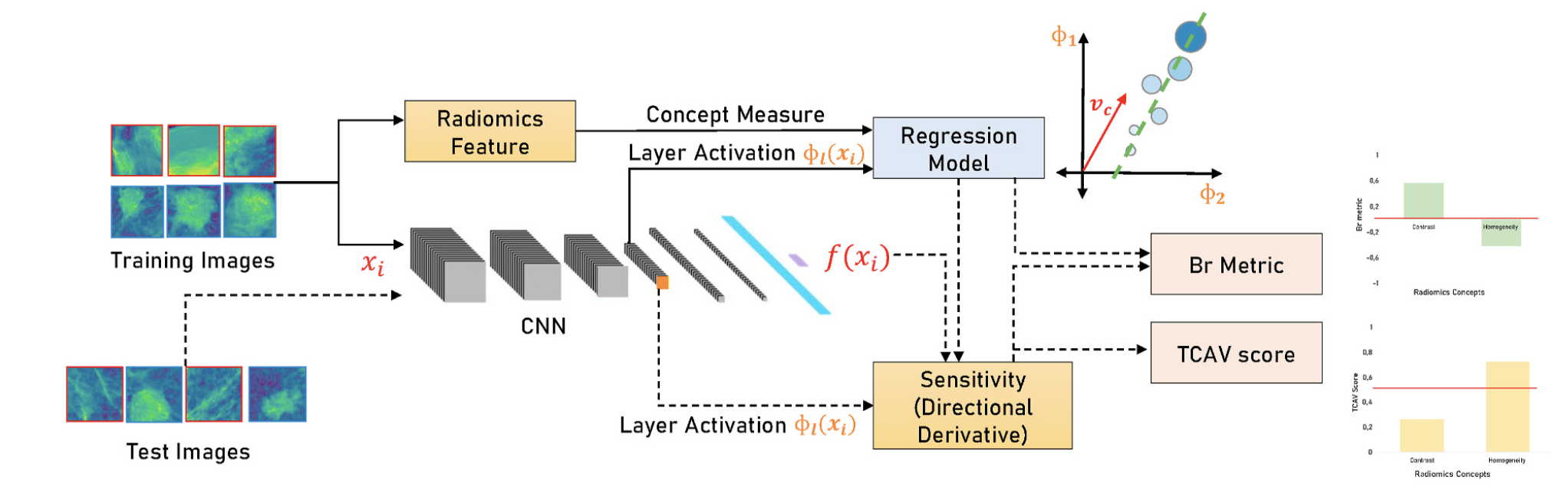
A similar idea in spirit that allows you to solve one of the shortcomings of the previous method – the likely drop in metrics. And again, nothing complicated – we consider the so-called radiomic features object (both basic, characterizing the shape or size, and specific to the task), and then we build models that try to predict the value of each feature from the representations from our neuron. Using these models, it is possible to estimate the sensitivity of the final prediction to the values of certain radiomic features for each input image. Details can be found in this article and in this.

We tried this approach for mammography – there are interesting results, some features can be predicted well from neural representations. It has not yet reached the sale, but it helped to generate hypotheses for adding hand-crafted features to the grid.
Case interpretation

Another group of methods is based on the search for similar cases among the library of pathologies. We considered such an idea – to give the doctor the ability to select an area in the image, calculate its representation, and then search in a vector database like Milvus similar areas among our labeled data. Again – so far it remains at the level of the idea.
counterfactual explanation

The method that refers us to the post about robust learning – we take RoI and try in some way (for example, with a generative network) to change it in such a way as to change the predicted class – for example, from malignant to benign or background. The changed areas can suggest what the mesh looks at and what properties of the object turned out to be decisive for it. I have not tried it myself, but intuitively I doubt that visually adequate perturbations will turn out.
Conclusion generation
There is a large group of articles that are aimed at generating a text opinion on a medical image. There are different approaches – using a fixed dictionary, free generation, filling empty spaces in the template. I haven’t personally seen anything in production, although we thought about it a lot.
What is the result?
As you probably guessed from the text, for us it still remains at the level of drawing and entertainment. The reason is simple – there is no certainty that the time spent will pay off with some kind of increased trust from users. At this stage, it seems that more attention should be paid simply to improving the quality of the models – we and our competitors are still far from the ideal. Although these methods will someday find their interesting applications – for example, in the educational process of young radiologists or automatic generation of detailed textual conclusions.
If you want to learn more about the organization of ML development processes, subscribe to our Telegram channel Cook ML
Similar Posts