How to survive a SQL database in the 21st century: clouds, Kubernetes and PostgreSQL multimaster

In the next open lesson, we talked about what challenges SQL databases faced in the era of clouds and Kubernetes. And at the same time we examined how SQL databases adapt and mutate under the influence of these calls.
The webinar was hosted by Valery Bezrukov, Google Cloud Practice Delivery Manager at EPAM Systems.
When the trees were small …
First, let's recall how the choice of a DBMS began at the end of the last century. However, it will not be difficult, because the choice of a DBMS in those days began and ended Oracle.

In the late 90s – the beginning of the noughties, in fact, there was no special choice, if we talk about industrial scalable databases. Yes, there were IBM DB2, Sybase, and some other databases that appeared and disappeared, but in general they were not so noticeable against Oracle. Accordingly, the skills of engineers of those times were somehow tied to the only choice that existed.
Oracle DBA should be able to:
– Install Oracle Server from the distribution;
– configure Oracle Server:
- init.ora;
- listener.ora;
– create:
- table spaces
- schemes;
- users
– back up and restore;
– carry out monitoring;
– deal with suboptimal requests.
At the same time, Oracle DBA was not particularly required:
- be able to choose the optimal DBMS or other technology for storing and processing data;
- provide high availability and horizontal scalability (this was not always a DBA issue);
- Good knowledge of the subject area, infrastructure, applied architecture, OS;
- perform loading and unloading of data, data migration between different DBMS.
In general, if we talk about the choice in those days, then it resembles a choice in a Soviet store in the late 80s:

Nowadays
Since then, of course, the trees have grown, the world has changed, and it has become something like this:

The DBMS market has also changed, as can be clearly seen from the latest Gartner report:

And here it should be noted that the clouds occupied their niche, the popularity of which is growing. If you read the same Gartner report, we will see the following conclusions:
- Many customers are on the way to transfer applications to the cloud.
- New technologies first appear in the cloud and it’s not a fact that they will ever move to cloud-free infrastructure.
- The pay-as-you-go pricing model has become familiar. Everyone wants to pay only for what they use, and this is not even a trend, but simply a statement of fact.
What now?
Today we are all in the cloud. And the questions that we have are questions of choice. And it is huge, even if we talk only about the choice of DBMS technologies in the On-premises format. We also have managed services and SaaS. Thus, the choice is becoming more complicated every year.
Along with questions of choice, limiting factors:
- price. Many technologies still cost money;
- skills. If we talk about free software, then the question of skills arises, since free software requires people who deploy and operate it with sufficient competence;
- functional. Not all services that are available in the cloud and built, say, even on the basis of the same Postgres, have the same features as Postgres On-premises. This is an essential factor that you need to know and understand. Moreover, this factor becomes more important than the knowledge of some hidden features of a single DBMS.
What are waiting for from DA / DE:
- a good understanding of the subject area and applied architecture;
- the ability to choose the right DBMS technology, taking into account the task;
- the ability to select the optimal method for implementing the selected technology in the context of the existing limitations;
- ability to perform data migration and migration;
- the ability to implement and operate the selected solutions.
Following example based on gcp demonstrates how the choice of a particular technology for working with data is arranged depending on its structure:

Note that PostgreSQL is missing in the schema, and all because it is hiding under the terminology Cloud sql. And when we get to Cloud SQL, we need to make a choice again:

It should be noted that this choice is not always clear, therefore application developers are often guided by intuition.
Total:
- The farther, the more urgent the question of choice becomes. And even if you look only at GCP, managed services and SaaS, then some mention of RDBMS appears only at the 4th step (and there is Spanner nearby). Plus, the choice of PostgreSQL appears in general at the 5th step, and next to it are MySQL and SQL Server, that is a lot, but you have to choose.
- We must not forget about the restrictions on the background of temptations. Mostly everyone wants Spanner, but it's expensive. As a result, a typical query looks something like this: “Please do Spanner for us, but for the price of Cloud SQL, well, you are professionals!”

What to do?
Without claiming to be the ultimate truth, let's say the following:
Need to change the approach to learning:
- to learn, as taught before DBA, it makes no sense;
- knowledge of one product is no longer enough;
- but to know dozens at the level of one is impossible.
You need to know not only and not how much the product, but:
- use case of its application;
- different deployment methods;
- advantages and disadvantages of each method;
- similar and alternative products in order to make an informed and optimal choice and not always in favor of a familiar product.
You also need to be able to migrate data and understand the basic principles of integration with ETL.
Real case
In the recent past, you had to make a backend for a mobile application. By the time it began to work on it, the backend had already been developed and was ready for implementation, and the development team spent about two years on this project. The following tasks were set:
- build CI / CD;
- to review architecture;
- put it all into operation.
The application itself was microservice, and the Python / Django code was developed from scratch and immediately in GCP. As for the target audience, it was assumed that there would be two regions – US and EU, and traffic was distributed through the Global Load balancer. All workloads and computational workloads worked in the Google Kubernetes Engine.
As for the data, there were 3 structures:
- Cloud Storage
- Datastore;
- Cloud SQL (PostgreSQL).
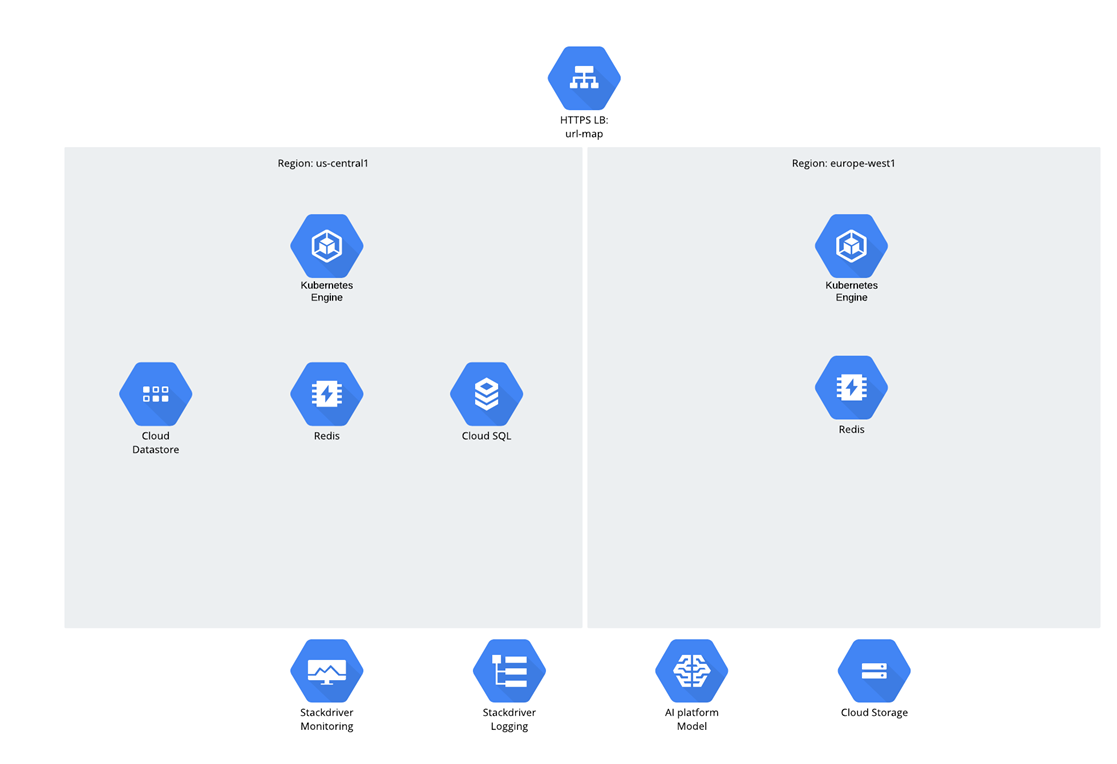
You may wonder why Cloud SQL was selected? To tell the truth, such a question in recent years has caused some awkward pause – there is a feeling that people began to be shy of relational databases, but nevertheless they continue to use them actively ;-).
For our case, Cloud SQL was chosen for the following reasons:
- As mentioned, the application was developed using Django, and it has a model for mapping persistent data from an SQL database to Python objects (Django ORM).
- The framework itself supported a fairly finite list of DBMSs:
- PostgreSQL
- MariaDB;
- MySQL
- Oracle
- SQLite
Accordingly, PostgreSQL was chosen intuitively from this list (well, it’s not Oracle to choose, in fact).
What was missing:
- the application was deployed only in 2 regions, and plans appeared 3rd (Asia);
- The database was in the North American region (Iowa);
- on the part of the customer there were concerns about possible access delays from Europe and Asia and outages in service in case of DBMS downtime.
Despite the fact that Django itself can work with several databases in parallel and divide them by reading and writing, there were not so many records in the application (more than 90% – reading). And in general, and in general, if one could do read-replica of the main base in Europe and Asia, this would be a compromise solution. Well, what's so complicated?
And the difficulty was that the customer did not want to abandon the use of managed services and Cloud SQL. And the possibilities of Cloud SQL are currently limited. Cloud SQL supports High availability (HA) and Read Replica (RR), but the same RR is supported in only one region. Having created a database in the American region, it is impossible to make a read-replica in the European region using Cloud SQL, although postgres itself does not interfere. Correspondence with Google employees did not lead to anything and ended with promises in the style of "we know the problem and are working on it, someday the issue will be resolved."
If you list the capabilities of Cloud SQL abstractly, it will look something like this:
1. High availability (HA):
- within one region;
- Through disk replication
- PostgreSQL mechanisms are not used;
- automatic and manual control possible – failover / failback;
- when switching, the DBMS is unavailable for several minutes.
2. Read Replica (RR):
- within one region;
- hot standby;
- PostgreSQL streaming replication.
In addition, as is customary, when choosing a technology you always come across some limitations:
– the customer did not want to produce entities and use IaaS, except through GKE;
– the customer would not want to deploy self service PostgreSQL / MySQL;
– Well, in general, Google Spanner would be quite suitable if it weren’t for its price, however, Django ORM cannot work with it, and so the thing is good.
Given the situation, the customer received a backfill question: “Can you do something similar to make it like Google Spanner, but it also works with Django ORM?”
Option No. 0
The first thing that came to mind:
- Stay within CloudSQL
- there will be no integrated replication between regions in any form;
- try to fasten the replica to the existing Cloud SQL by PostgreSQL;
- somewhere and somehow start the PostgreSQL instance, but at least master does not touch.
Alas, it turned out that this can’t be done, because there is no access to the host (it’s in another project altogether) – pg_hba and so on, and there is still no access under superuser.
Option No. 1
After further reflection and taking into account the previous circumstances, the train of thought changed somewhat:
- we are still trying to stay within the framework of CloudSQL, but we are switching to MySQL, because Cloud SQL by MySQL has an external master, which:
– is a proxy for external MySQL;
– looks like a MySQL instance;
– invented for data migration from other clouds or On-premises.
Since setting up MySQL replication does not require access to the host, in principle everything worked, but it is very unstable and inconvenient. And when we went further, it became completely scary, because we deployed the entire structure with terraform’s, and suddenly it turned out that the external master was not supported by terraform’s. Yes, Google has a CLI, but for some reason everything worked every once in a while – it’s created, it’s not created. Perhaps because the CLI was invented for data migration outside, and not for replicas.
Actually, on this it became clear that Cloud SQL does not fit the word at all. As they say, we did everything we could.
Option No. 2
Since it did not work to stay within Cloud SQL, we tried to formulate requirements for a compromise solution. The requirements were as follows:
– Work in Kubernetes, the maximum use of resources and capabilities of Kubernetes (DCS, …) and GCP (LB, …);
– the lack of ballast from a pile of unnecessary things in the cloud like HA proxy;
– the ability to run HA PostgreSQL or MySQL in the main region; in other regions – HA from the RR of the main region plus its copy (for reliability);
– multi master (I did not want to contact him, but it was not very important).
As a result of these demands, the horizon has finally appeared on the horizon.suitable DBMS and binding options:
- MySQL Galera;
- CockroachDB;
- PostgreSQL tools
:
– pgpool-II;
– Patroni.
MySQL Galera
MySQL Galera technology was developed by Codership and is a plugin for InnoDB. Features:
- multi master;
- synchronous replication
- reading from any node;
- record to any node;
- built-in HA mechanism;
- There is a Helm chart from Bitnami.
Cockroachdb
According to the description, the thing is completely bombastic and is an open source project written in Go. The main participant is Cockroach Labs (founded by immigrants from Google). This relational DBMS was originally created to be distributed (with horizontal scaling out of the box) and fault tolerant. Its authors from the company outlined the goal of "combining the richness of SQL functionality with the horizontal availability familiar to NoSQL solutions."
Of the nice bonus is support for the postgres connection protocol.
Pgpool
This is an add-on for PostgreSQL, in fact, a new entity that takes over all the connections and processes them. It has its own loader balancer and parser, licensed under the BSD license. It provides ample opportunities, but it looks somewhat frightening, because the presence of a new entity could become a source of some additional adventures.
Patroni
This is the last thing that the eye fell on, and, as it turned out, not in vain. Patroni is an open source utility, which, in essence, is a Python daemon that allows you to automatically maintain PostgreSQL clusters with various types of replication and automatic role switching. The piece turned out to be very interesting, since it integrates well with the cuber and does not carry any new entities.
What ultimately chose
The choice was not easy:
- Cockroachdb – fire, but dumb;
- MySQL Galera – also not bad, where it is used a lot, but MySQL;
- Pgpool – a lot of extra entities, so-so integration with the cloud and K8s;
- Patroni – excellent integration with K8s, no extra entities, integrates well with GCP LB.
Thus, the choice fell on Patroni.
conclusions
The time has come to summarize. Yes, the world of IT infrastructure has changed significantly, and this is only the beginning. And if earlier clouds were just another type of infrastructure, now everything is different. Not only that, innovations in the clouds are constantly appearing, they will appear and, perhaps, they will appear only in the clouds and only then, with the help of startups, they will be transferred to On-premises.
As for SQL, then SQL will live. This means that PostgreSQL and MySQL must be known and you need to be able to work with them, but more importantly, to be able to apply them correctly.





