How to structure an ML project and make it reproducible and maintainable
When creating projects in machine learning, it is often the hardest thing to get started. What should be the structure of the repository? What standards to follow? Will your colleagues be able to reproduce the results of the experiments? The author of the material shares a project template developed over the years of studying data science, and our the flagship course on Data Science starts on January 25.
Instead of trying to find the perfect repository structure on your own, wouldn’t it be better to have a template to start with?
That’s why I created a template data-science-templatewhich summarizes the best practices I’ve learned from years of working on structuring data science projects.
This template is the culmination of years of my search for the best data science project structure. It will allow you:
- create a readable project structure;
- effectively manage dependencies in the project;
- create short and readable commands for repetitive tasks;
- restart only modified data pipeline components;
- Observe and automate code;
- enable type hints during code execution;
- check for problems in the code before committing changes (before committing);
- automatically document code;
- automatically run tests on commit.
This is a lightweight template, it uses only tools that can be universal for different cases:
- Poetry: Python dependency management.
- Prefect: Organize and view the data pipeline.
- Pydantic: data validation with type annotations in Python.
- pre-commit plugins: formatting, testing and documenting code according to best practices.
- Makefile: automate repetitive tasks with short commands.
- GitHub Actions: automation of the pipeline of continuous integration and continuous deployment of applications (CI / CD).
- pdoc: automatic documentation for your project’s API.
Begin
Start with installation Cookiecutter to download a template:
pip install cookiecutterCreate a project based on the template:
cookiecutter https://github.com/khuyentran1401/data-science-templateAnd try it out according to these instructions.
Next, some important features of the template will be discussed in detail.
The project structure based on this template is standardized and easy to understand:

Here is a brief description of the roles of these files:
├── data
│ ├── final # данные после тренировки модели
│ ├── processed # данные после обработки
│ ├── raw # сырые данные
├── docs # документация проекта
├── .flake8 # конфигурация инструмента форматирования
├── .gitignore # игнорируемые при коммите в Git файлы
├── Makefile # хранит команды настройки среды
├── models # хранит модели
├── notebooks # хранит интерактивные блокноты
├── .pre-commit-config.yaml # конфигурация pre-commit
├── pyproject.toml # зависимости poetry
├── README.md # описание проекта
├── src # хранит исходники
│ ├── __init__.py # делает src модулем Python
│ ├── config.py # хранит конфигурации
│ ├── process.py # обрабатывает данные перед обучением модели
│ ├── run_notebook.py # выполняет блокноты
│ └── train_model.py # тренирует модель
└── tests # хранит тесты
├── __init__.py # делает tests модулем Python
├── test_process.py # тестирует функции в process.py
└── test_train_model.py # тестирует функции в train_model.py Poetry is a dependency management tool in Python, an alternative to pip. With it, you can:
- separate main dependencies and sub-dependencies into two separate files (instead of keeping all dependencies in requirements.txt)
- remove all unused subdependencies when uninstalling a library
- avoid installing new packages that conflict with existing ones
- package your project in a few lines of code
Poetry installation instructions can be found here.
Makefile allows you to create short and readable commands for tasks. If you are unfamiliar with Makefile, check out this quick guidel.
A Makefile can be used to automate tasks such as setting up the environment:
initialize_git:
@echo "Initializing git..."
git init
install:
@echo "Installing..."
poetry install
poetry run pre-commit install
activate:
@echo "Activating virtual environment"
poetry shell
download_data:
@echo "Downloading data..."
wget https://gist.githubusercontent.com/khuyentran1401/a1abde0a7d27d31c7dd08f34a2c29d8f/raw/da2b0f2c9743e102b9dfa6cd75e94708d01640c9/Iris.csv -O data/raw/iris.csv
setup: initialize_git install download_dataNow, when people want to set up an environment for your projects, all they have to do is:
make setup
make activateAnd the sequence of commands will be executed!

make is useful if you want to run a task whenever its dependencies change.
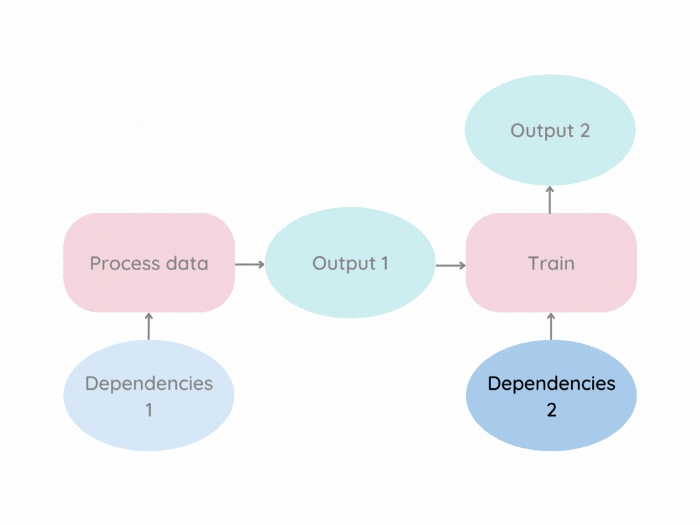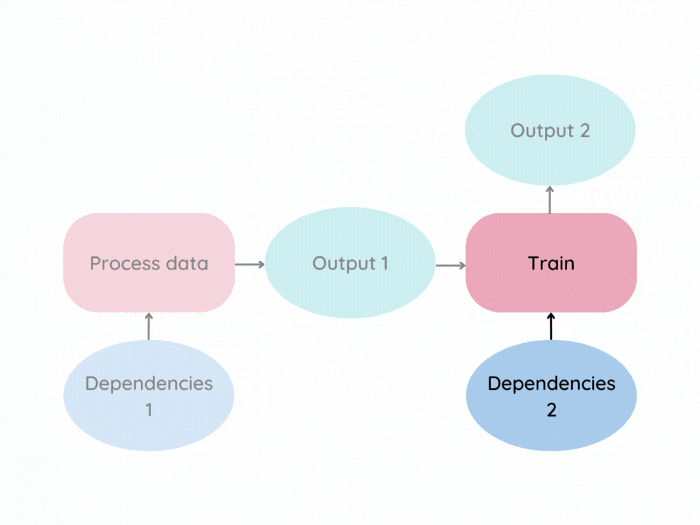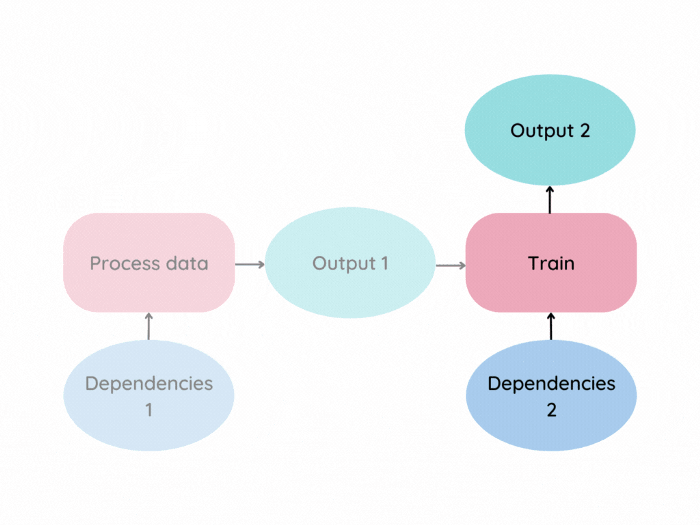
As an example, let’s depict the file association in the Makefile:

data/processed/xy.pkl: data/raw src/process.py
@echo "Processing data..."
python src/process.py
models/svc.pkl: data/processed/xy.pkl src/train_model.py
@echo "Training model..."
python src/train_model.py
pipeline: data/processed/xy.pkl models/svc.pkTo create a models/svc.pkl file, you can run:
make models/svc.pklBecause data/processed/xy.pkl and src/train_model.py are prerequisites for the models/svc.pkl target, make runs the creation recipes for both data/processed/xy.pkl and models/svc.pkl.
Processing data...
python src/process.py
Training model...
python src/train_model.pyIf there are no changes to the models/svc.pkl prerequisite, make will skip updating models/svc.pkl.
This way make will help you avoid wasting time running unnecessary tasks.
This template uses Prefectto watch launches from Perfect UI:

Among other things, Prefect can help:
- retry when your code doesn’t work;
- schedule code execution;
- send notifications about failures in the flow (flow).
You can access these functions by simply turning your function into flow Prefect.
from prefect import flow
@flow
def process(
location: Location = Location(),
config: ProcessConfig = ProcessConfig(),
):
...Pydantic is a Python library for data validation using type annotations.
Pydantic Models set the data types for the flow parameters and check their values when the flow is executed.

If the field value does not match the type annotation, you will get an error at runtime:
process(config=ProcessConfig(test_size="a"))pydantic.error_wrappers.ValidationError: 1 validation error for ProcessConfig
test_size
value is not a valid float (type=type_error.float)All Pydantic models stored in file src/config.py.
Before committing to Git, you need to make sure that the code:
- passes unit tests
- complies with best practices and style guides
However, manually checking these criteria can be tedious. pre-commit – a framework that identifies problems in the code before the commit.
You can add various plugins to the pre-commit pipeline. Before committing, the files will be checked for compliance with the standards of the relevant tools – these are black, flake, isort and iterrogate. If the checks fail, the code will not be committed.

All plugins in this template can be found in this file

Data scientists often interact with other team members when working on a project. Therefore, it is very important to create good documentation. To generate API documentation based on the docstrings of your Python files and objects, run the command:
make docs_viewConclusion:
Save the output to docs...
pdoc src --http localhost:8080
Starting pdoc server on localhost:8080
pdoc server ready at http://localhost:8080The documentation can now be seen at http://localhost:8080:

GitHub Actions automate the integration of the application, speed up the assembly, testing and deployment of the code.
Tests from the tests folder when creating a commit performed automatically.

Congratulations! You just learned how to use a template to create an ML project that you can reuse and edit. This template is designed to be flexible. Feel free to adjust the project to suit your needs.

Data Science and Machine Learning
Python, web development
Mobile development
Java and C#
From basics to depth
As well as





