How to quickly and easily search for data with Whale

This article describes the simplest and fastest data discovery tool that you see working on KDPV. Interestingly, whale is designed to be hosted on a remote git server. Details under the cut.
How Airbnb’s data discovery tool changed my life
In my career, I’ve been fortunate enough to work on some fun problems: I studied flow mathematics during my degree at MIT, worked on incremental models, and on an open source project. pylift at Wayfair, as well as implementing new home page targeting models and CUPED improvements on Airbnb. But all this work was never glamorous – in fact, I often spent most of my time searching, exploring, and validating data. While this was a persistent condition at work, it didn’t occur to me that it was an issue until I got to Airbnb where it was solved with a data discovery tool – Dataportal…
Where can I find {{data}}? Dataportal…
What does this column mean? Dataportal…
How’s {{metric}} doing today? Dataportal…
What is a sense of life? AT Dataportal, probably.
Okay, you presented a picture. Finding data and understanding what it means, how it was created and how to use it – all this takes only a few minutes, not hours. I could spend my time drawing simple conclusions, or new algorithms (… or answering random questions about the data), rather than rummaging through notes, writing repeated SQL queries, and mentioning colleagues in Slack to try to recreate context. that someone else already had.
What’s the problem?
I realized that most of my friends did not have access to such a tool. Few companies are willing to devote huge resources to building and maintaining a platform tool like Dataportal. While there are several open source solutions out there, they are generally designed to scale, making it difficult to set up and maintain without a dedicated DevOps engineer. So I decided to create something new.
Whale: a silly data discovery tool

And yes, by simple to stupidity I mean simple to stupidity. Whale has only two components:
- A Python library that collects metadata and formats it in MarkDown.
- Rust command line interface for searching this data.
From the point of view of the internal infrastructure, there are only a lot of text files and a text updating program for maintenance. That’s it, so hosting on a git server like Github is trivial. No new query language to learn, no management infrastructure, no backups. Git is known to everyone, so syncing and collaboration is free. Let’s take a closer look at the functionality Whale v1.0…
Full featured git based GUI
Whale is built to sail in the ocean of a remote git server. is he very easy is customizable: define some connections, copy the Github Actions script (or write it for your chosen CI / CD platform) and you have a web-based data discovery tool right away. You will be able to search, view, document and share your spreadsheets directly on Github.
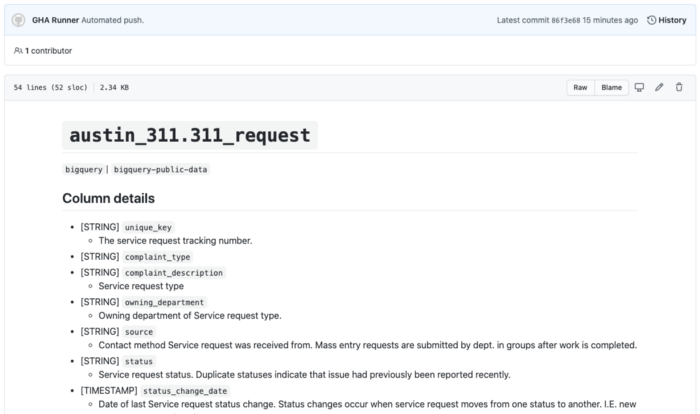
An example of a stub table generated using Github Actions. Full working demo see in this section…
Lightning fast CLI search for your repository
Whale lives and breathes on the command line, providing powerful, millisecond lookups across your tables. Even with millions of tables, we managed to make whale incredibly performant by using some clever caching mechanisms and rebuilding the backend in Rust. You will not notice any search lag [привет, Google DS]…
Whale demo, search a million tables…
Automatic calculation of metrics [в бете]
One of my least favorite things as a data scientist is running the same queries over and over again just to check the quality of the data being used. Whale supports the ability to define metrics in plain SQL that will run on a schedule along with your metadata cleanup pipelines. Define a YAML metrics block inside the stub table and Whale will automatically run on schedule and run nested metrics queries.
```metrics
metric-name:
sql: |
select count(*) from table
```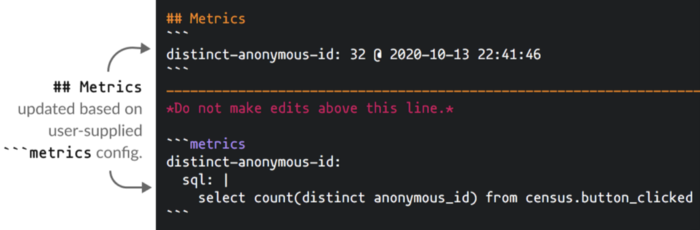
Combined with Github, this approach means whale can serve as an easy central source of truth for metric definitions. Whale even stores the values along with the timestamp in the ~ /. whale / metrics “if you want to do some kind of graph or deeper research.
Future
After talking with users of our pre-release versions of whale, we realized that people need more functionality. Why a table lookup tool? Why not a metrics search tool? Why not monitoring? Why not a SQL query execution tool? Although whale v1 was originally intended as a simple CLI companion tool Dataportal/Amundsen, it has already evolved into a fully functional standalone platform, and we hope that it will become an integral part of the data scientist toolkit.
If there is something that you want to see in the development process, join our the Slack community, open Issues on Github, or even contact directly LinkedIn… We already have a whole host of cool features – Jinja templates, bookmarks, search filters, Slack alerts, Jupyter integration, even a CLI panel for metrics – but we’d love your input.
Conclusion
Whale is developed and supported by Dataframe, a startup that I recently had the pleasure of starting with other people. While whale is designed for data scientists, Dataframe is for data teams. For those of you who want to collaborate more closely, feel free to address, we will add you to the waiting list.

And according to the promo code HABR, you can get an additional 10% to the discount indicated on the banner.
- Online bootcamp for Data Science
- Training the Data Analyst profession from scratch
- Data Analytics Online Bootcamp
- Teaching the Data Science profession from scratch
- Python for Web Development Course
- Data Analytics Course
- DevOps course
- Profession Web developer
- The profession of iOS developer from scratch
- Profession Android developer from scratch
- The profession of Java developer from scratch
- JavaScript course
- Machine Learning Course
- Course “Mathematics and Machine Learning for Data Science”
- Advanced Course “Machine Learning Pro + Deep Learning”
Recommended articles
- How to Become a Data Scientist Without Online Courses
- 450 free courses from the Ivy League
- How to learn Machine Learning 5 days a week for 9 months in a row
- How much does a data analyst earn: an overview of salaries and vacancies in Russia and abroad in 2020
- Machine Learning and Computer Vision in the Mining Industry