How to make thematic modeling of a forum quickly or what bothers people with celiac disease
Last year I needed to urgently improve my knowledge in the field of machine learning. I am a product manager for Data Science, Machine Learning and AI, or in another way Technical Product Manager AI / ML. Business skills and the ability to develop products, as is usually the case in projects aimed at users not in the technical field, are not enough. You need to understand the basic technical concepts of the ML industry, and if necessary, be able to write an example yourself to demonstrate the product.
For about 5 years I have been developing Front-end projects, developing complex web applications on JS and React, but I have never dealt with machine learning, laptops and algorithms. So when I saw the news from Otusthat they have opened a five-month experimental course on Machine Learning, without hesitation, I decided to undergo trial testing and got on the course.
For five months, every week there were two-hour lectures and homework for them. There I learned about the basics of ML: various regression algorithms, classifications, model ensembles, gradient boosting and even slightly affected cloud technologies. In principle, if you carefully listen to each lecture, then there are enough examples and explanations for homework. But still, sometimes, like in any other coding project, I had to turn to the documentation. Given my full time employment, it was quite convenient to study, since I could always revise the record of an online lecture.
At the end of the training of this course, everyone had to take the final project. The idea for the project arose quite spontaneously, at which time I started training in entrepreneurship at Stanford, where I got on the team that worked on the project for people with celiac intolerance. During the market research, I was interested to know what worries, what they are talking about, what people with this feature complain about.
As the study progressed, I found a forum on celiac.com with a huge amount of material on celiac disease. It was obvious that scrolling manually and reading more than 100 thousand posts was impractical. So the idea came to me, to apply the knowledge that I received in this course: to collect all the questions and comments from the forum from a specific topic and make thematic modeling with the most common words in each of them.
Step 1. Data collection from the forum
The forum consists of many topics of various sizes. In total, this forum has about 115,000 topics and about a million posts, with comments on them. I was interested in a specific subtopic “Coping with Celiac Disease”, which literally means “Cope with Celiac disease”, if in Russian, it means more “continue to live with a diagnosis of celiac disease and somehow cope with difficulties”. This sub-topic contains about 175,000 comments.
Data downloading occurred in two stages. To begin with, I had to go through all the pages under the topic and collect all the links to all posts, so that in the next step, I could already collect a comment.
url_coping = 'https://www.celiac.com/forums/forum/5-coping-with-celiac-disease/'Since the forum turned out to be quite old, I was very lucky and there weren’t any security troubles on the site, so to collect the data, it was enough to use a combination User agent from the library fake_useragent, Beautiful soup to work with html markup and know the number of pages:
# Get total number of pages
def get_pages_count(url):
response = requests.get(url, headers={'User-Agent': UserAgent().chrome})
soup = BeautifulSoup(response.content, 'html.parser')
last_page_section = soup.find('li', attrs = {'class':'ipsPagination_last'})
if (last_page_section):
count_link = last_page_section.find('a')
return int(count_link['data-page'])
else:
return 1
coping_pages_count = get_pages_count(url_coping)And then download the HTML DOM of each page to easily and easily pull data from them using the Python library BeautifulSoup.
# collect pages
def retrieve_pages(pages_count, url):
pages = []
for page in range(pages_count):
response = requests.get('{}page/{}'.format(url, page), headers={'User-Agent': UserAgent().chrome})
soup = BeautifulSoup(response.content, 'html.parser')
pages.append(soup)
return pages
coping_pages = retrieve_pages(coping_pages_count, url_coping)
To download the data, I needed to determine the necessary fields for analysis: find the values of these fields in the DOM and save them in dictionary. I myself came from the Front-end background, so working with home and objects was trivial for me.
def collect_post_info(pages):
posts = []
for page in pages:
posts_list_soup = page.find('ol', attrs = {'class': 'ipsDataList'}).findAll('li', attrs = {'class': 'ipsDataItem'})
for post_soup in posts_list_soup:
post = {}
post['id'] = uuid.uuid4()
# collecting titles and urls
title_section = post_soup.find('span', attrs = {'class':'ipsType_break ipsContained'})
if (title_section):
title_section_a = title_section.find('a')
post['title'] = title_section_a['title']
post['url'] = title_section_a['data-ipshover-target']
# collecting author & last action
author_section = post_soup.find('div', attrs = {'class':'ipsDataItem_meta'})
if (author_section):
author_section_a = post_soup.find('a')
author_section_time = post_soup.find('time')
post['author'] = author_section_a['data-ipshover-target']
post['last_action'] = author_section_time['datetime']
# collecting stats
stats_section = post_soup.find('ul', attrs = {'class':'ipsDataItem_stats'})
if (stats_section):
stats_section_replies = post_soup.find('span', attrs = {'class':'ipsDataItem_stats_number'})
if (stats_section_replies):
post['replies'] = stats_section_replies.getText()
stats_section_views = post_soup.find('li', attrs = {'class':'ipsType_light'})
if (stats_section_views):
post['views'] = stats_section_views.find('span', attrs = {'class':'ipsDataItem_stats_number'}).getText()
posts.append(post)
return posts
In total, I collected about 15,450 posts in this topic.
coping_posts_info = collect_post_info(coping_pages)Now they could be transferred to the DataFrame so that they lay there beautifully, and at the same time saved them in a csv file so that you did not have to wait again when the data was collected from the site if notebook accidentally broke or I accidentally redefined a variable where.
df_coping = pd.DataFrame(coping_posts_info,
columns =['title', 'url', 'author', 'last_action', 'replies', 'views'])
# format data
df_coping['replies'] = df_coping['replies'].astype(int)
df_coping['views'] = df_coping['views'].apply(lambda x: int(x.replace(',','')))
df_coping.to_csv('celiac_forum_coping.csv', sep=',')After collecting a collection of posts, I proceeded to collecting the comments themselves.
def collect_postpage_details(pages, df):
comments = []
for i, page in enumerate(pages):
articles = page.findAll('article')
for k, article in enumerate(articles):
comment = {
'url': df['url'][i]
}
if(k == 0):
comment['question'] = 1
else:
comment['question'] = 0
# collecting comments
comment_section = article.find('div', attrs = {'class':'ipsComment_content'})
if (comment_section):
comment_section_p = comment_section.find('p')
if(comment_section_p):
comment['comment'] = comment_section_p.getText()
comment['date'] = comment_section.find('time')['datetime']
author_section = article.find('strong')
if (author_section):
author_section_url = author_section.find('a')
if (author_section_url):
comment['author'] = author_section_url['data-ipshover-target']
comments.append(comment)
return comments
coping_data = collect_postpage_details(coping_comments_pages, df_coping)
df_coping_comments.to_csv('celiac_forum_coping_comments_1.csv', sep=',')
STEP 2 Data Analysis and Thematic Modeling
In the previous step, we collected data from the forum and received the final data in the form of 153777 lines of questions and comments.
But just the data collected is not interesting, so the first thing I wanted to do was very simple analytics: I derived statistics for the top 30 most viewed topics and 30 most commented topics.
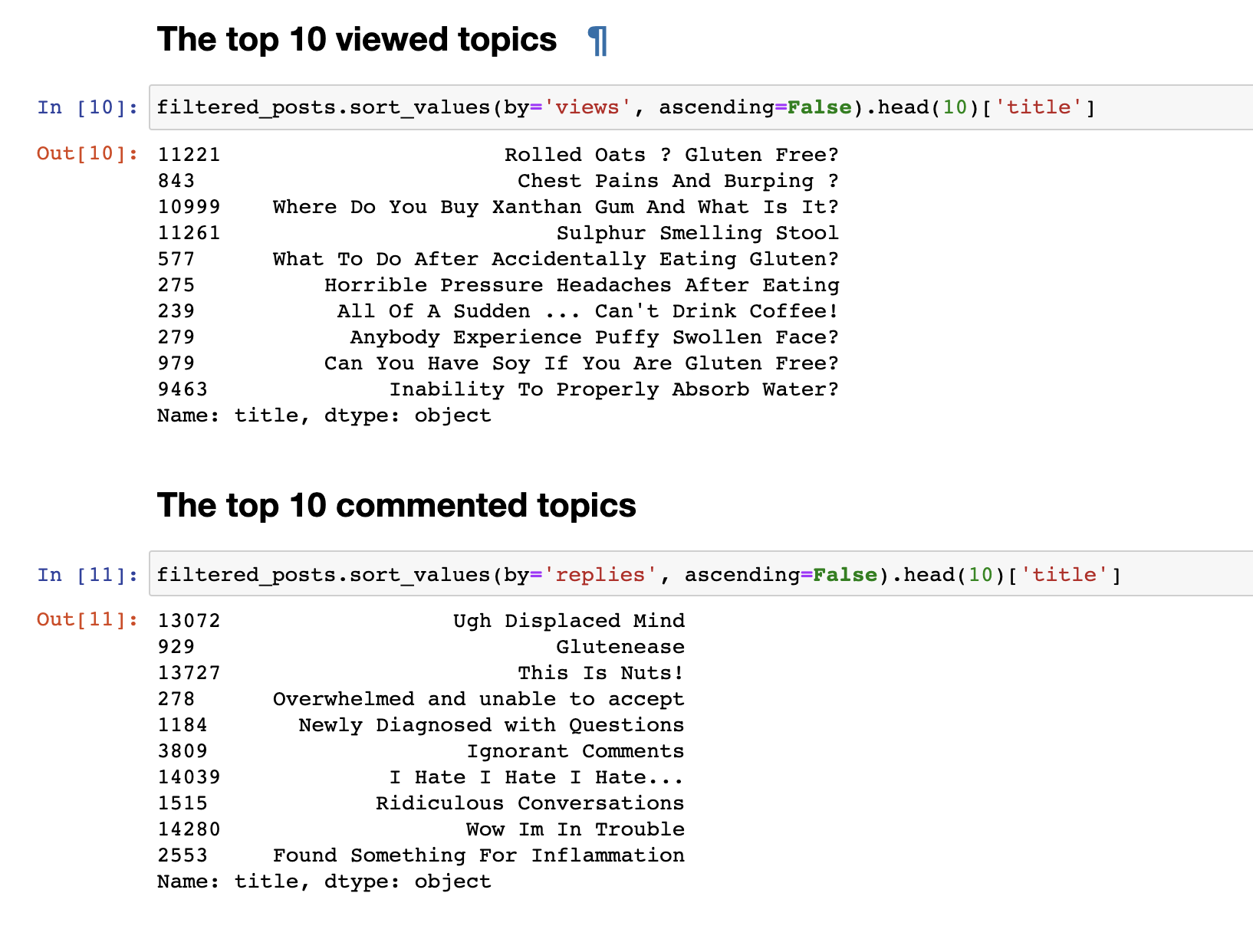
The most viewed posts did not coincide with the most commented ones. The titles of commented posts, even at first glance, are noticeable. Their names have a more emotional color: “I hate, I hate, I hate” or “Arrogant comments ” or “Wow, I’m in trouble”. And the most viewed, more have a question format: “Is it possible to eat soy?”, “Why can’t I properly absorb water?” other.
We did a simple text analysis. To go directly to a more complex analysis, you need to prepare the data itself before submitting it to the input of the LDA model for a breakdown by topic. To do this, get rid of comments containing less than 30 words, in order to filter out spam and meaningless short comments. We bring them to lowercase.
# Let's get rid of text < 30 words
def filter_text_words(text, min_words = 30):
text = str(text)
return len(text.split()) > 30
filtered_comments = filtered_comments[filtered_comments['comment'].apply(filter_text_words)]
comments_only = filtered_comments['comment']
comments_only= comments_only.apply(lambda x: x.lower())
comments_only.head()Delete unnecessary stop words to clear our text selection
stop_words = stopwords.words('english')
def remove_stop_words(tokens):
new_tokens = []
for t in tokens:
token = []
for word in t:
if word not in stop_words:
token.append(word)
new_tokens.append(token)
return new_tokens
tokens = remove_stop_words(data_words)We’ll also add bigrams and form a bag of words to highlight strong phrases, for example, like gluten_free, support_group, well, other phrases that, when grouped, carry a certain meaning.
bigram = gensim.models.Phrases(tokens, min_count=5, threshold=100)
bigram_mod = gensim.models.phrases.Phraser(bigram)
bigram_mod.save('bigram_mod.pkl')
bag_of_words = [bigram_mod[w] for w in tokens]
with open('bigrams.pkl', 'wb') as f:
pickle.dump(bag_of_words, f)
Now we are finally ready to directly train the LDA model itself.
id2word = corpora.Dictionary(bag_of_words)
id2word.save('id2word.pkl')
id2word.filter_extremes(no_below=3, no_above=0.4, keep_n=3*10**6)
corpus = [id2word.doc2bow(text) for text in bag_of_words]
lda_model = gensim.models.ldamodel.LdaModel(
corpus,
id2word=id2word,
eval_every=20,
random_state=42,
num_topics=30,
passes=5
)
lda_model.save('lda_default_2.pkl')
topics = lda_model.show_topics(num_topics=30, num_words=100, formatted=False)
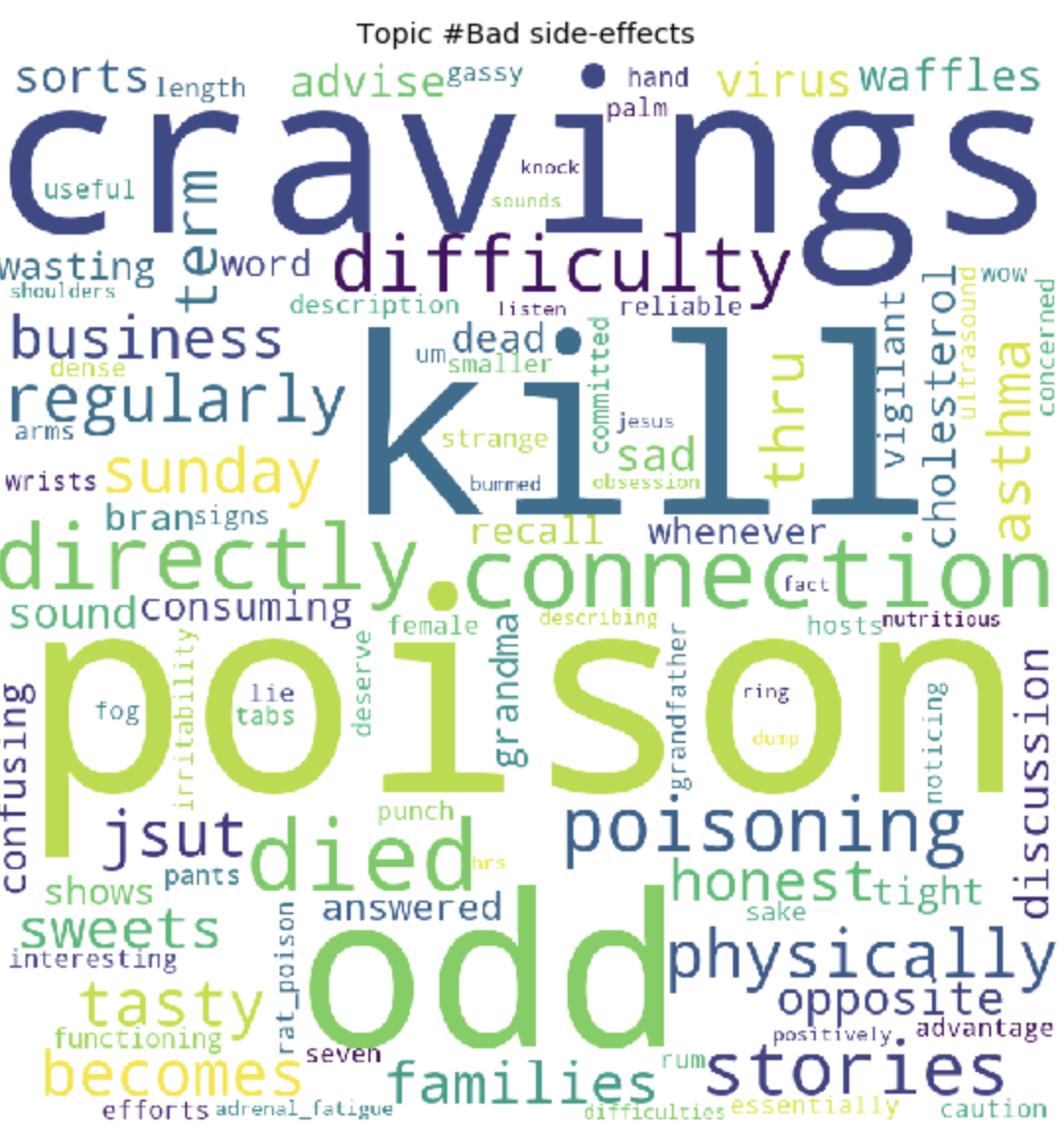
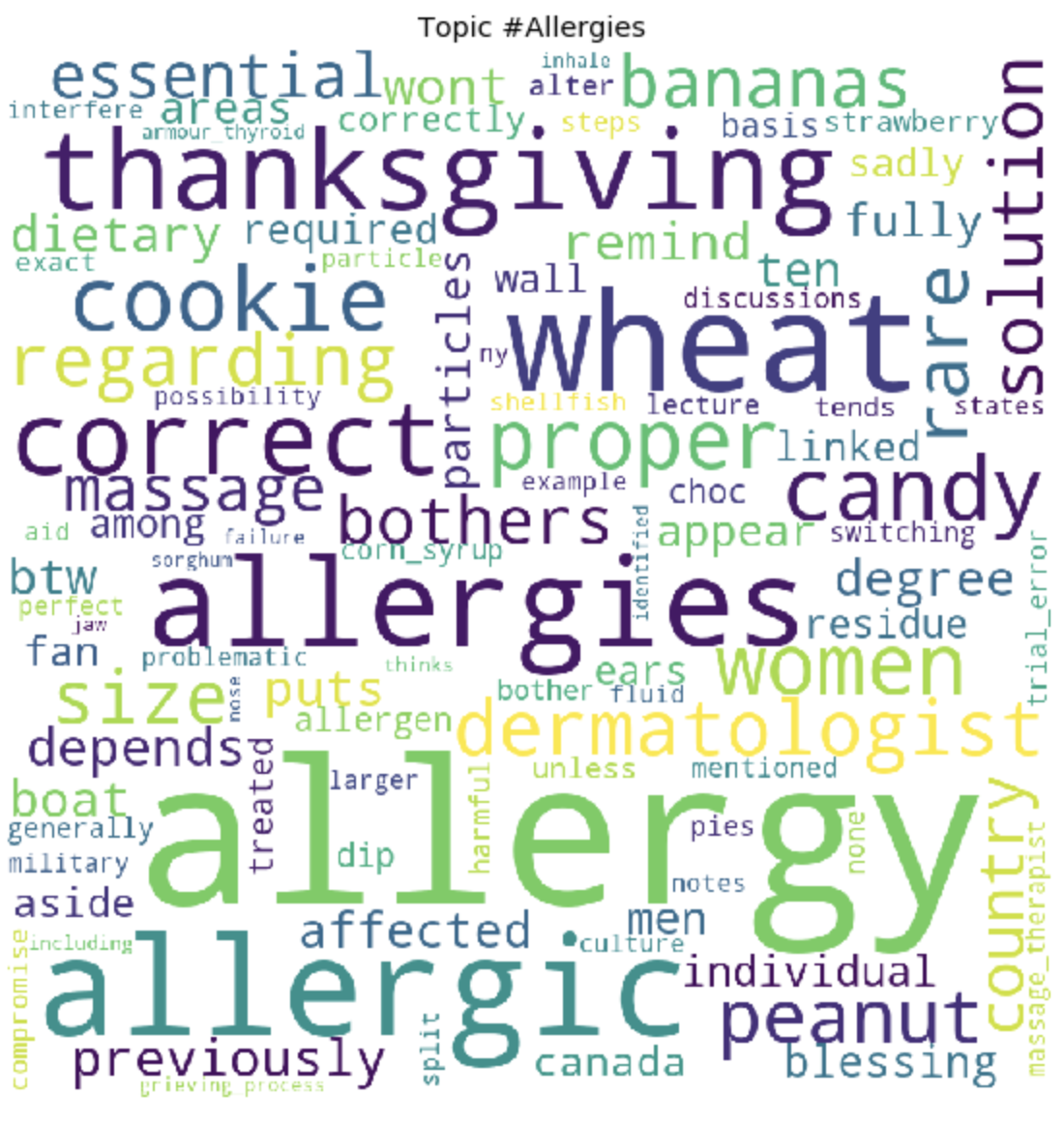
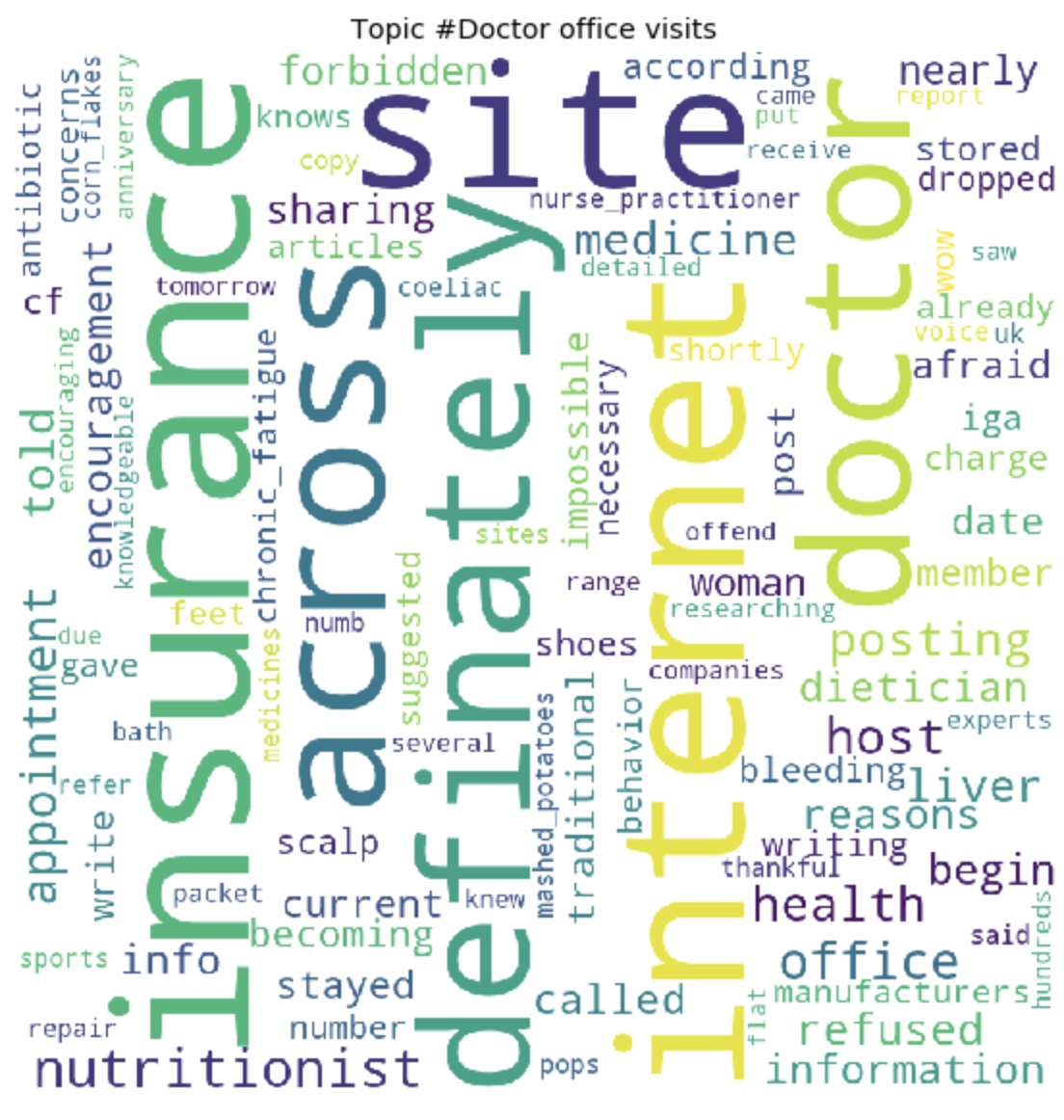
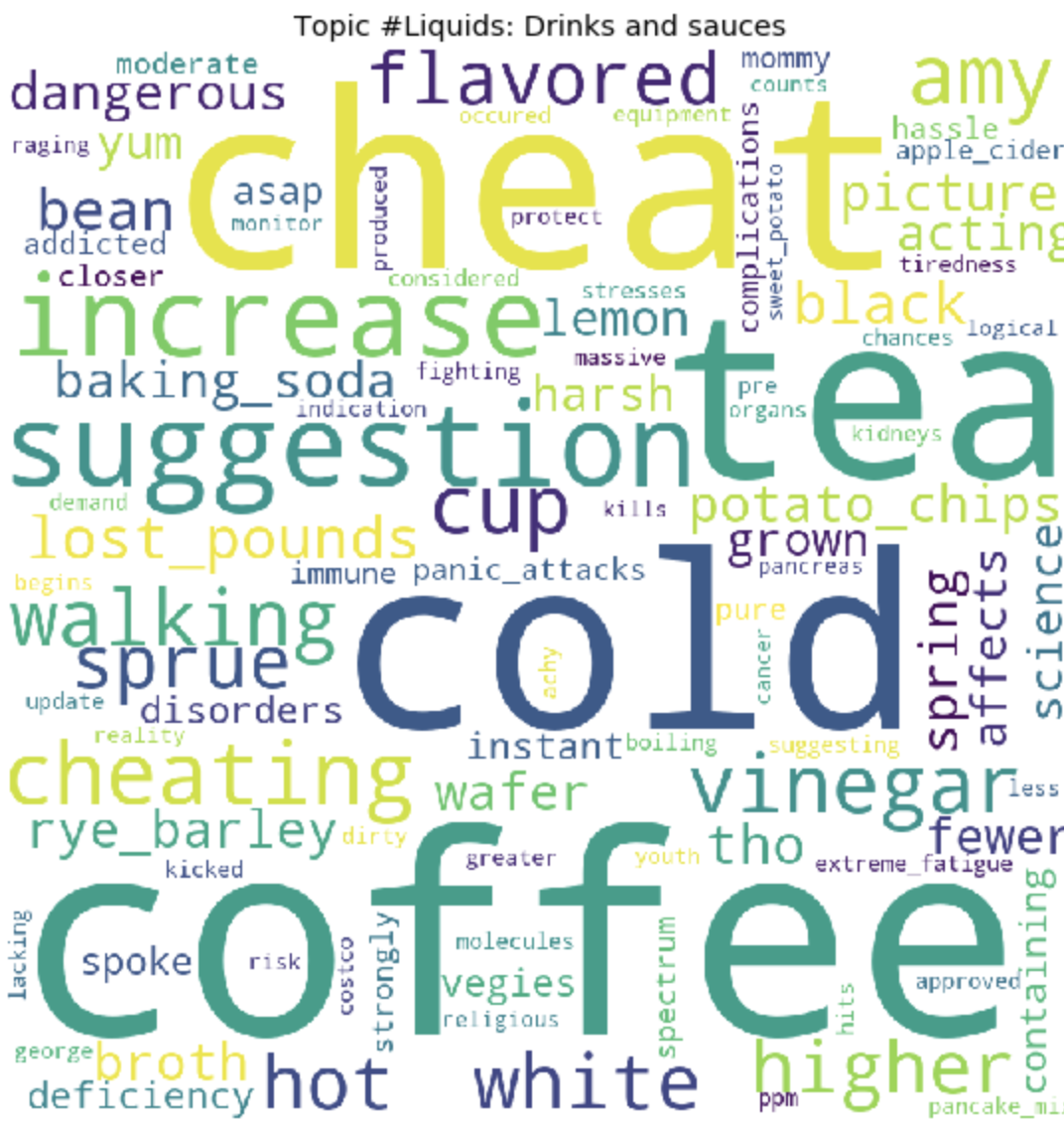
At the end of the training, we ultimately get the result of the formed topics. Which I attached at the end of this post.
for t in range(lda_model.num_topics):
plt.figure(figsize=(15, 10))
plt.imshow(WordCloud(background_color="white", max_words=100, width=900, height=900, collocations=False)
.fit_words(dict(topics[t][1])))
plt.axis("off")
plt.title("Topic #" + themes_headers[t])
plt.show()
As it may be noticeable, the topics turned out to be quite distinct in content from each other. According to them, it becomes clear what people are talking about with celiac intolerance. Basically, about food, going to restaurants, contaminated food with gluten, terrible pains, treatment, going to doctors, family, misunderstanding and other things that people have to face every day in connection with their problem.
That’s all. Thank you all for your attention. I hope you find this material interesting and useful. And yet, since I’m not a DS developer, do not judge strictly. If there is something to add or improve, I always welcome constructive criticism, write.
To view 30 topics