How to create a knowledge base so that it becomes an “intellectual asset” of the company
In September 2020, I acted as a speaker IV-th conference “Corporate Knowledge Management”held as part of the corporate training week. My master class “How to create a corporate knowledge base so that it becomes an” intellectual asset “of the company” interested the audience, and I decided to make an article out of the materials of my speech. I would be glad if the text helps you in your work. I would be glad if any of you would like to discuss this post in the comments.
 Source
SourceThere is no universal scenario “How to create a knowledge base” that would suit everyone and always. This is due to both different approaches to organizing databases and different IT tools. But the general requirements, a kind of cookbook, is the subject of my article.
The experience of a large multi-level information system support project allows us to distinguish three main principles that underlie any successful knowledge base. She must be:
- understandable;
- relevant;
- affordable.
Write clearly for everyone
 Source
SourceThe text of the article from the knowledge base should be understandable to everyone who will read it. Moreover, it is clear from the first reading, because most likely the second time it will simply not be read. The article should not be too long or too short. The material should be presented in such a way that the interpretations of its content were unambiguous, and there was no need to translate from “accounting” or “IT-shny” to “human”.
For example, an article describing a solution to a typical problem, written in the style of “… clear the cache before entering your personal account”, is likely to raise questions, but if you supplement it with a cache clearing algorithm written “for your grandmother”, then the answer will be clear to everyone.
The situation becomes more acute when the knowledge base is used as a FAQ for external users, the level of training of which varies from grandparents who could not master a smartphone, to super-professionals in this field.
At first glance, it seems that it is impossible to achieve this: if an article was written for a “teapot”, then it will be redundant for those immersed in the topic, and if you focus on the pros, then the “teapot” will need a “translation”. How to be?
There are many tools out there to help solve problems. In the Department of corporate systems LANIT we use three approaches.
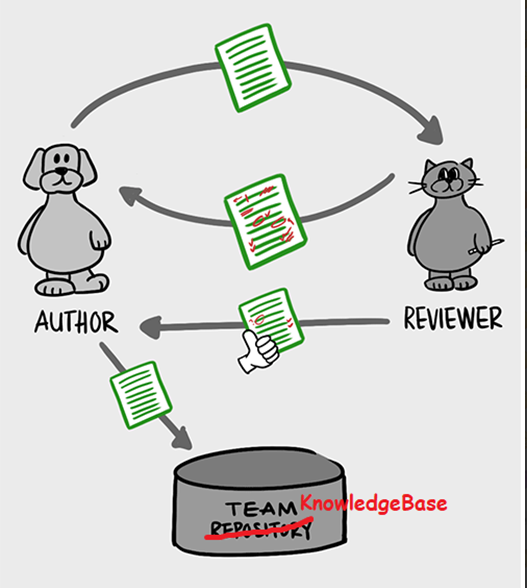
1. Review from a leading subject matter expert. The process is aimed at improving the quality of the knowledge base materials (hereinafter KB). The bottom line is that the expert checks the correctness of the presentation of the material, including the consistency and consistency of the presentation.
 Source
Source2. Feedback from users in the form of an assessment and suggestions for expanding / reducing / changing the wording, order of presentation / structuring, etc., based on the results of using the material. Anyone interested can leave feedback. Suggestions and wishes are being worked out. Technically, this can be implemented in the form of ratings of responses from users, likes, thanks, etc.
3. Structuring. This tool can be conditionally divided into two types of impacts:
- administrative action – a regulated order of presentation in a uniform style, the procedure for fixing changes, additions, etc.;
- technical solutions – the use of macros and add-ons that allow you to disclose details and transcripts only if necessary. This solves the issue of different levels of training of readers: for a specialist, the article will be as short as possible in the language of professional requirements, and for a beginner it will contain explanations of terms and links to articles on related issues.
For example, articles describing an algorithm for solving typical problems have the following structure:
Always up to date
Once you have placed information in the knowledge base, you must always keep it up to date. All users of the knowledge base should always have confidence in the materials posted in it.

In fact, the knowledge manager should have its own monitoring system, which will have its own triggers and clearly described response algorithms.
For example, for the knowledge base of the information system support service, the trigger will be the release of a new version, changes in legislation, etc. Development of a set of triggers and actions when they occur, as well as determining those responsible for their implementation is a task the solution of which provides a significant share of the success of the knowledge base …
A triggered trigger means that you need to quickly adjust the materials. In order for the update not to become a nightmare, at the stage of posting materials, you need to think about how to optimize the number of articles and, if necessary, automatically select the ones you need according to the specified parameters.
We use classifiers and statuses (a status model with a specific transition algorithm) as a tool that allows us to automatically select articles. At the same time, it is a difficult task to create classifiers so that their composition is sufficient, but not redundant.
An example of a status model:
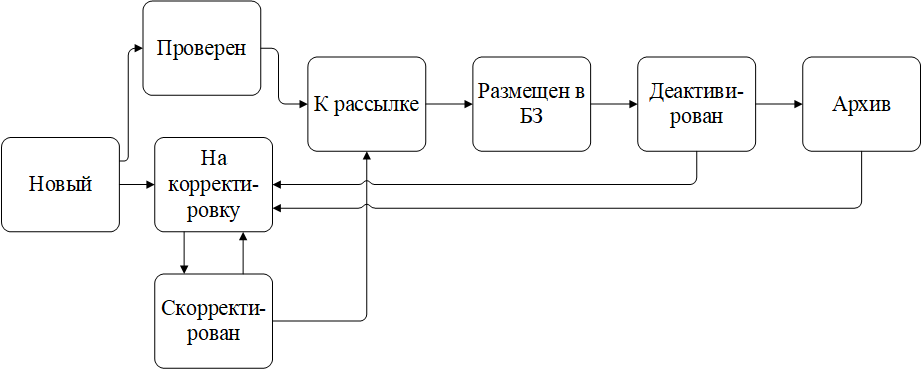
How not to create an information trash can instead of a knowledge base
Articles that answer irrelevant questions or have narrowly worded headings are a way to create an information “trash bin” instead of a knowledge base. The title, which is not worded broadly enough, means that at the right time only those who know that it is in the knowledge base will be able to find such an article. The rest will start solving the problem from scratch and create a duplicate article based on this solution.
For example, the heading “Statement Templates” is correct, but narrowly worded. It will be easier to search if you add keywords to it and write like this: “Application templates: vacation, time off, remote work, dismissal, transfer.”
Statistics on the use of knowledge base materials helps to solve the problem. Based on usage statistics, we can find rarely used ones and either send them to the archive (if the material is no longer relevant), or expand, ensuring popularity in the future.
Articles assembled according to the Lego principle of constants and variables reduce the cost of the knowledge base
There is a rule, which we did not come to right away, but which significantly saves time on maintaining the relevance of the knowledge base. This rule is no duplication! The information is recorded once, then links to it are used. Technically, there are a lot of opportunities to “inject” constants into the right places in the text of the article so that the reader does not even know that the article as a constructor consists of parts.

Why “does not fly”
Even the most up-to-date knowledge base containing answers to all popular questions may not take off if it is difficult to find the information you need.
The search problem can be solved by structuring and multi-level classification. Moreover, the classification should be not only at the level of sections of the KB catalog, but also with labels on different topics (for example, if we have a knowledge base of the user support service, then by topics, personal accounts, etc.). Each user can select a list of articles according to specified criteria using the advanced search form.
In order for the search to be of the highest quality for a specific user, a role-based access model is implemented in the knowledge base. This, firstly, solves the issue of potential information leakage: only those materials are available to the user that are suitable for their role in the project or in the organization as a whole, and, secondly, they narrow the list of materials among which the search is made, increasing the quality of the results.
Mobility is our everything
For mobility and due to the popularity of Telegram, we are additionally developing a chat bot.
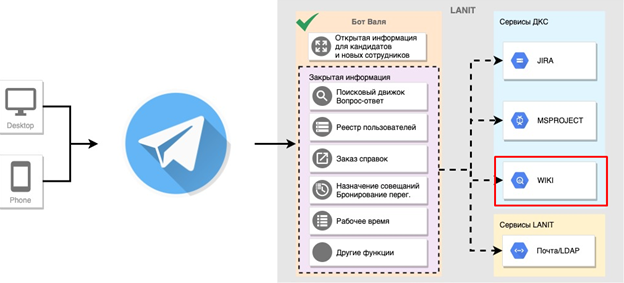
The bot is implemented in Telegram and is available from any user device. The level of access to information through the bot corresponds to the level of access to the company’s services. Upon request, the answer can also be obtained from the wiki.
Each answer can be appreciated. The grading system allows for timely corrections of both answers and classifiers. Questions, answers to which were not found, are collected separately and serve as ideas for the development of the knowledge base.
The principles considered are not an exhaustive list of requirements for the knowledge base, formulated over four years of active work on several projects, including on the knowledge base of the support service of a large state information system. In addition, it should be noted that all principles and rules work when all users and authors are interested in the knowledge base. The main metrics for assessing interest are the number of materials used in the work and the number of edits from each author. My personal list of requirements is constantly expanding and in the last year there are more and more nuances to the requirement to structure articles. I will gladly share it in the next article.