How to become a DevOps engineer in six months or even faster. Part 5. Deployment
How to become a DevOps engineer in six months or even faster. Part 2. Configuration
How to become a DevOps engineer in six months or even faster. Part 3. Versions
How to become a DevOps engineer in six months or even faster. Part 4. Software packaging

Refresh the memory
The image above shows what a typical code deployment should look like. Let me remind you where we are now in accordance with the roadmap:

If you spent a month studying each section, you are now at 4 months. By this time, you should already know how to provide the infrastructure that will work with your software, how to properly manage software versions, and how to package them for future deployment. In this article, we will discuss how to properly deploy your code!
Code Deployment
Did you notice that I said “how to”, and not “how easy”? It is not just that. Unfortunately, the correct deployment of code from the development environment to the prod environment is still a painful process, fraught with errors and crashes. There are many reasons for this, but, in my opinion, it comes down mainly to the differences between the environment in which the code is created and the environment in which it is executed.
Minimizing these differences is the best thing you can do not only during the deployment process, but also during its execution after deployment. So, how do we reduce and / or eliminate the differences between our prod and non-prod environments?
And it works on my car!
If your dev infrastructure looks like this:

And the prod infrastructure is like this:

Consider your problem. If you use the infrastructure as-a-code, and do not configure things manually, then you can solve it by 90%. If not, do not despair – you are not alone. Highlight the afternoon, determine what gaps you have (learning, culture, people, processes, etc.) and methodically fill them one by one.
The bottom line is that you will not succeed in managing a modern technology stack if you are still manually configuring things. This is an axiom. The first thing you need to do is make sure that everything related to prod is the versioned artifact deployed by your deployment server.
Assuming all this has been done, I will take the liberty of asserting that the best way to deploy code is to not deploy it at all.
Modern Deployment Approach
It is true that deploying code on machines is an echo of the 1990s. The biggest problem when deploying code to a set of production machines is that, by definition, your prod servers (on which the code is executed) are different from your dev servers (where this code is written). It is not surprising that immediately after deployment there are a lot of problems that have never been noticed before, because now the conditions have changed!
So before you deploy, you need to make sure that your deployment artifact is the entire runtime, not part of the code. In other words, deploy your code once in the development environment, clone the entire machine your code is running on, and then copy it wherever it should be.

This is called “immutable deployment” and is a very powerful template that will save you many hours of headache after deployment. Of course, if you run containers, the same idea applies: you deploy the same container everywhere. You can say: “stop! My prod is different from dev! ”And that’s right, because the database usernames / passwords, connection strings, S3 dumpster locations are all different things! Yes, they are very different things.
The way to solve this problem is to use the principle of 12 factor app config. An application of twelve factors stores the configuration in env vars, or env environment variables. Environment variables can be easily changed between deployments without changing the code. Unlike configuration files, there is less likelihood of accidentally storing them in a code repository, and unlike custom configuration files or other configuration mechanisms, such as Java System Properties, they are a language and operating system independent standard. Thus, your entire configuration must be externalized and transferred as environment variables to your computer.
For example, if you are in AWS, use SSM as an external repository of parameters – it integrates perfectly with CloudFormation. It is also very easy to set environment variables directly from AWS ssm cli commands. Of course, other cloud providers have similar mechanisms.
Also, resist the urge to “fix” your prod machines when something goes wrong. Machines must be immutable, which means that all corrections you make must come from dev. Your goal should be to prevent access to prod machines at all. Neither ssh, nor scp, nor prod access – never to anyone, not to himself, nor to novice hackers.
But what if I need logs to fix the problem? You guessed it – your magazines should also be externalized, ideally sent to another location, either using the ElasticSearch / Logstash / Kibana (ELK) stack, or using commercial software such as SumoLogic or Datadog.
Whatever you do, your prod machines are a “working cattle” that is replaced at the slightest sign of ill health. They are not “pets” that need to be cared for in order to be cured by spending hours troubleshooting.
I know that this analogy is used too often, and I hear from people who really care about cattle that this is not entirely true, but the essence is the same – do not “repair” your prod-machines, just fix your development and redeploy it .
Code Deployment Mechanics
So, you know what to do, but you don’t know how. Unfortunately, this is where Jenkins appears. If you don’t know, then Jenkins is one of the most popular open source deployment automation servers.
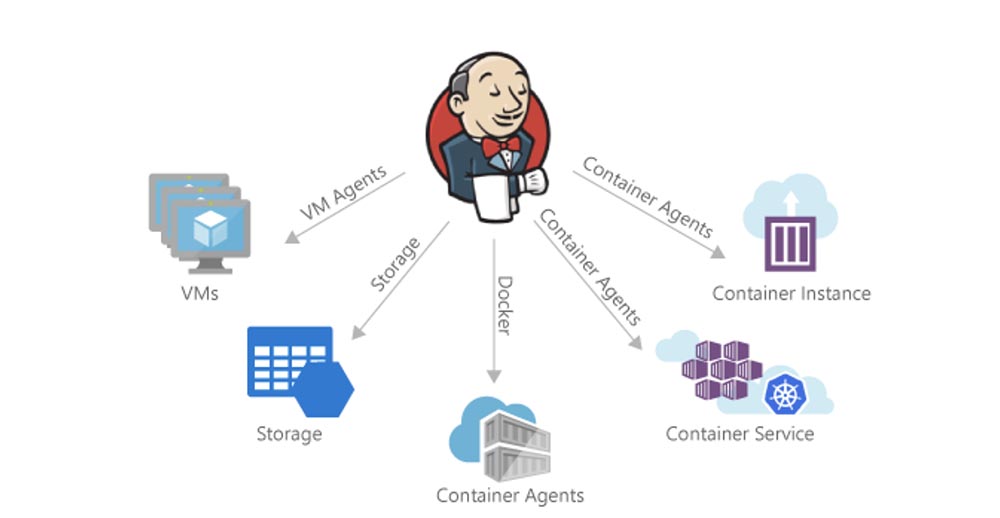
I say “unfortunately” because Jenkins (and his predecessor Hudson) have been around us for almost ten years, and this is noticeable. It is complicated to set up and even more difficult to maintain. It comes with millions of plugins of dubious quality. These plugins, as a rule, break at the most inopportune time, dropping everything else behind them. In fact, truly stable, Jenkins workshops are rare and usually only seen in the largest organizations.
Why do I recommend you start with Jenkins? Because, despite all its shortcomings, it is still extremely popular and widely used in the IT field. Jenkins knowledge, in particular of how structured Jenkinsfileis a huge advantage for job prospects and cannot be overlooked. When learning Jenkins, make sure you take on the new Pipeline plugin Blue ocean, not the legacy Jenkins jobs pipeline. This is critical if you want your CI / CD pipeline to live right inside your GitHub / GitLab repo code. Thus, the pipeline itself is a versioned piece of code!

In fact, it is so important that it is worth repeating again: everything is code! Your application, how it is deployed, how it is tracked, how it is configured, etc. are all appropriately versioned code snippets stored in GitHub / GitLab / Anywhere. The goal of this is to create an environment free of inconsistencies for the main developers (software engineers who write functional code).
For example, I should be able to:
- write your own little microservice;
- add any tests that I consider necessary;
- Add Jenkinsfile
- add monitoring-as-code configuration;
- specify my parameters in the env.yaml file;
- save all this in one repository;
- make Jenkins automatically detect the specified repository;
- build your microservice;
- test it;
- Expand (using the Canary or Blue-Green method);
- arrange sending a message to your e-mail when this is done!
This is the goal, the achievement of which is the essence of the core mission of DevOps engineers.
Alternatives to Jenkins
As I said earlier, Jenkins has existed for ages, and today there are others, in my opinion, the best, albeit less popular alternatives. One of them is a service. Codedeploy from AWS. It has limitations, but the developers have made significant improvements over the past year, and if you work in AWS, I urge you to try CodeDeploy.
The second alternative is the GitLab CI continuous integration module. If your organization is running GitLab, you should probably start working with it, as it is pretty neatly integrated with the rest of GitLab.
Finally, GitHub has announced its own application deployment tool. Actions, which is supported by their own automation.
In fact, I don’t think that tools are so important here. It is important to know that everything, including code deployment pipelines, is versioned artifacts, and nothing goes to prod unless it comes from dev.
Regardless, if you start with Jenkins, try setting it up as a container. It’s not very difficult and will be a terrific opportunity to learn how to deploy a Jenkins container server with Jenkins expandable, container work nodes. In fact, you can start without any container orchestration, which is the subject of the next article.
To be continued very soon …
A bit of advertising 🙂
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to your friends, cloud VPS for developers from $ 4.99, A unique analogue of entry-level servers that was invented by us for you: The whole truth about VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps from $ 19 or how to divide the server? (options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
Dell R730xd 2 times cheaper at the Equinix Tier IV data center in Amsterdam? Only here 2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV from $ 199 in the Netherlands! Dell R420 – 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB – from $ 99! Read about How to Build Infrastructure Bldg. class c using Dell R730xd E5-2650 v4 servers costing 9,000 euros for a penny?