How OSINT helps identify outbreaks
To save people, you need speed. And open data sources just allow this speed to get. OSINT makes it possible to monitor new data in real time and learn about epidemics 1-2 weeks earlier than official announcements. And in the case where every day can take thousands of lives, this time is critically important.
In turn, the traditional version of epidemic monitoring is longer and more expensive, although at the same time more accurate. The infected person needs to understand that something is wrong with him, come to the hospital, take tests. Doctors must make a diagnosis, and after identifying some dangerous disease, send the data to the health authorities for action.
In developing countries, the traditional disease monitoring system may be completely absent or very ineffective. In this case, OSINT is generally the only way to prevent or reduce the effect of an outbreak.
In addition to speed, the advantage of OSINT is that it is available to most. This gives the population the opportunity to monitor the alleged outbreaks in their region and, in which case, in time to protect themselves and loved ones.
However, open data is not magic that will save everyone. OSINT will not help predict the appearance of the virus, but based on a pair of identified cases, you can predict a possible epidemic and try to prevent it. And if the spread of the disease is already in full swing, open data will help reduce the number of cases.
We select the right sources
Social networks
Twitter – One of the most common social networks for the early detection of epidemics. Often in short messages, people share their well-being and use keywords that are exactly what they need for monitoring. In addition, this network has a relatively open policy with access to 1% random sample of tweets.
Searching for hints of an epidemic on Twitter might look like this. Tweets uploaded for a certain period of time are filtered out in the classifier SVM by:
– keywords like “colds” (or other illness) in the language of the region. It’s also good to add a filter to tweets in which a person writes about himself (“me”, “me”, “me”) and that he is got infected (“Picked up”), and not just afraid.
– to a specific region (local data will be more accurate – at the level of settlements). There’s a geolocation system on Twitter for this – Carmen.
And you also need to exclude retweets, news and links.
Why is Twitter monitoring so effective in detecting outbreaks? In one research tweet data from October 2012 to May 2013 showed a correlation of 0.93 in relation to official data from the Centers for Disease Control and Prevention in the United States. While even the data from the US Department of Health and Human Services were less accurate – a correlation of 0.75. And it’s worth understanding that Twitter can be monitored daily and learn first-hand information. And users there can write about their health quite frankly.
Of course, Twitter should not be the only source of monitoring. ~ 4% of the world’s population sits there monthly. But Twitter should pay special attention in the regions where it has the largest number of active users.
In addition to Twitter, it will be useful to monitor other social networks to achieve the initial goal.
For example, there was interesting case with WeShat (just for COVID-19). They have a WeChat Index resource that allows you to determine the frequency of mentions of certain keywords. So, in the period from 11/17/2019 to 12/30/2019 (a few weeks before the official announcement and laboratory confirmation), the WeChat Index was filled with the words “flu”, “shortness of breath”, “diarrhea”, “new coronavirus”.
No less effective can to be Facebook. For example, the locations of the most violent outbreaks are determined from a network of contacts. There is a Facebook Data For Good platform for this. There you can access the service Social Connectedness Index (only for NGOs and researchers), which will show the regions with the closest ties. The service determines the relationship between Facebook friendships and the location of people. This allows you to understand where people are more in contact with each other, and where you need to enter a more strict quarantine.
Google searches
The epidemic trend is determined by the number of queries related to the symptoms, the name of the disease, certain medications, etc. To date, the most affordable tools for this method are Google Trends.
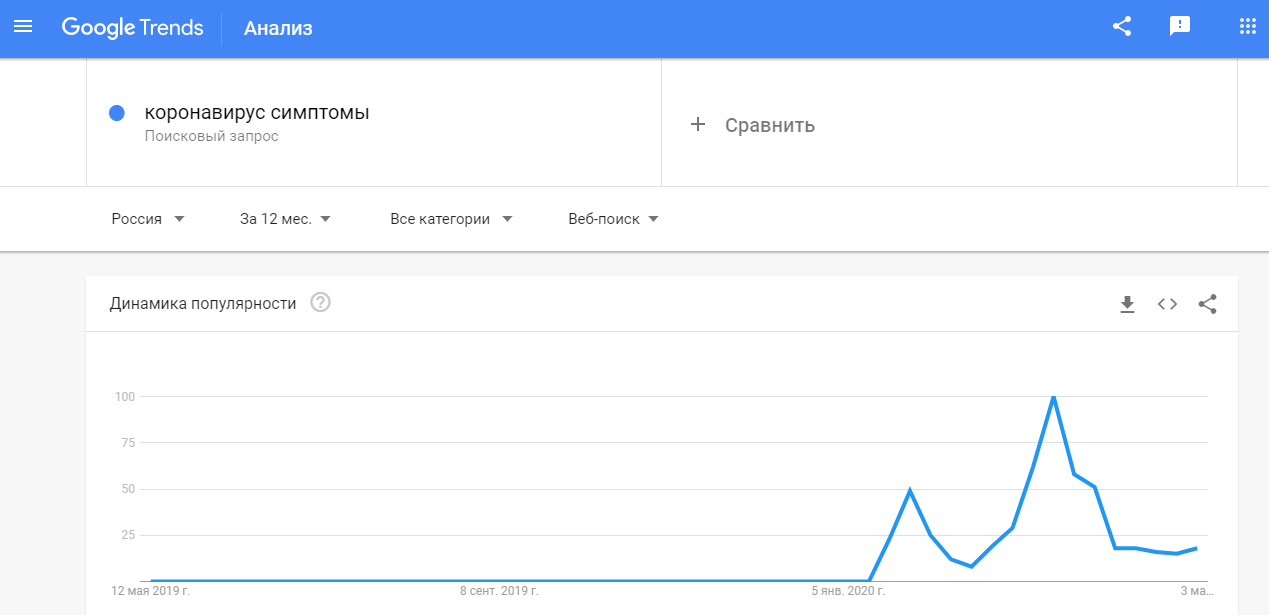
The first two patients with coronavirus in Russia were recorded on January 31. And Google Trends shows that increased interest in the virus in the search engine in the country began to appear 2 weeks before.
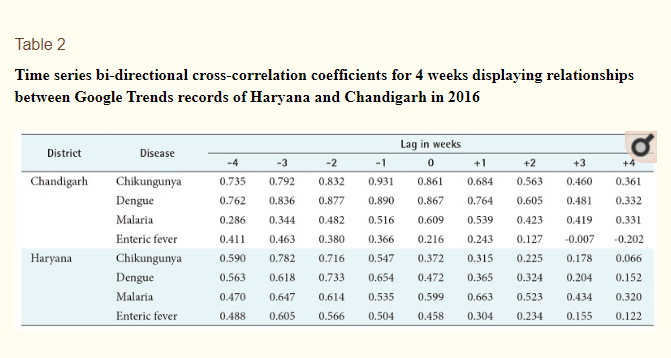
Researchers from India went even further and made a correlation between two sources of open data – between data on 4 diseases from the Integrated Disease Surveillance Project and from Google Trends and Correlate. And according to their results, some outbreaks could be foreseen already in 4 weeks.
In addition to predicting outbreaks, analysis of search queries will help determine approximately when the epidemic is on the decline.
Query analytics may be less accurate and produce late results (data is updated weekly). Therefore, it is especially good in combination with other methods.
Wikipedia Articles Popularity
Searching for information on Google often results in a Wikipedia page. While Google shows us which topics they are currently looking for the most, Wikipedia shows which topics people are really interested in (that they even went to the resource to read about them).
Wikipedia provides the ability to track the number of times an article has been viewed for specific periods of time. This means that you can track when an article becomes more popular. Information is provided quickly, as it is updated every hour. You can see it here or (a simpler option, but the data is only for a month) go to a specific article → on the left in the “tools” click on “page information” → on the page that opens, in the first plate below will be “the number of page views in the last 30 days” → to the right the number you click on and see the statistics for the month.
Here, for example, article statistics COVID-19 in Russian.
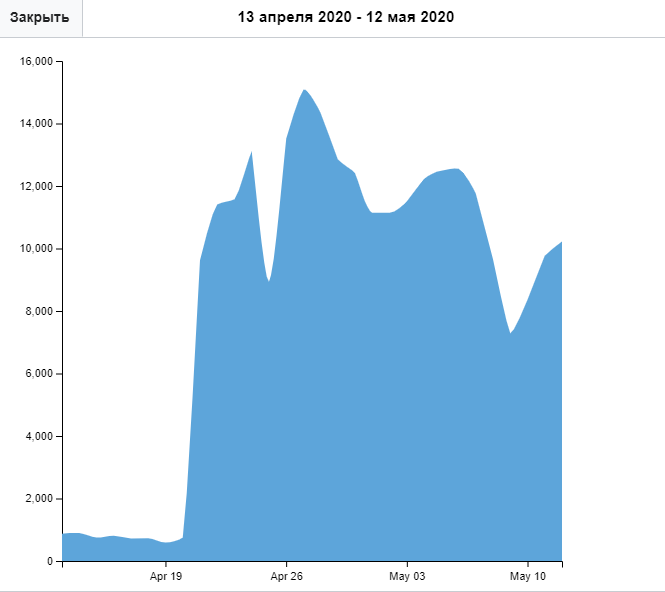
In theory, nothing prevents us from collecting such an open statistics on all pages with illnesses every day with some kind of script to determine our trends in addition to Google Trends. Of course, we will not be able to follow the article about some rare and unusual disease, but articles about the most frequently occurring infectious diseases can be easily monitored.
Detailed statistics on various parameters can be viewed here. For example, popular articles are filtered by month and day, as well as by specific language. To do this, go to “Total Page Views”, click “Top viewed articles” on the left and select the language and time period. Here, for example, top articles in Russian for January 2020.
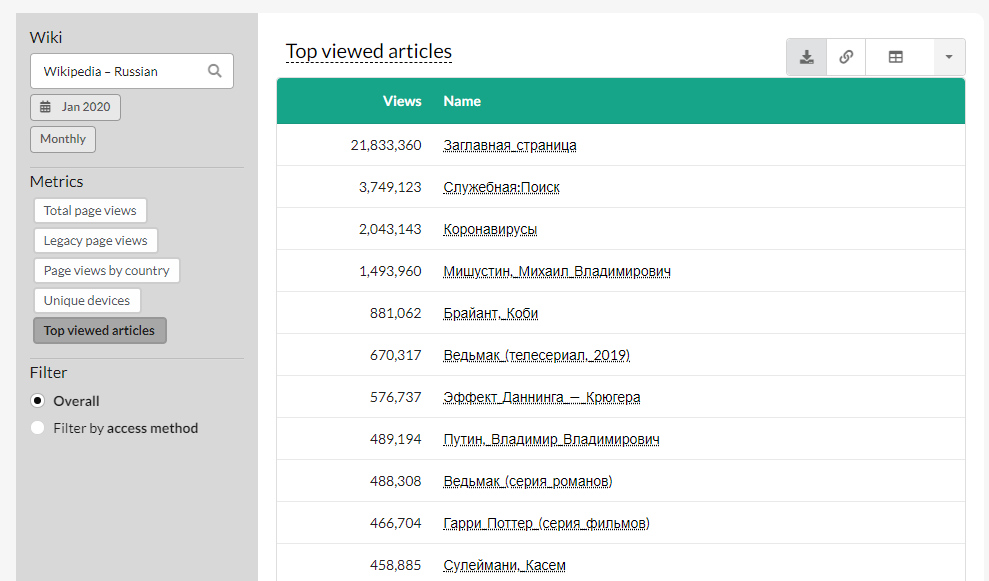
If suddenly some articles about diseases (especially infectious ones) begin to be pushed forward – perhaps this is an alarming bell.
Wikipedia allows you to monitor data in real time, that is, it also gives information faster than official announcements, on average for 2 weeks.
Getting data through crowdsourcing
In the OSINT environment, no one forbids creating new sources of information by attracting people interested in this information. In this case, the user himself comes to our resource and leaves data about his health. All of this is anonymous, but helps locate new outbreaks. That is, in online mode, you can see where the cases of diseases appeared and where they are most.
This format is good in that a person may not be able or unwilling to go to the doctor. And with ready-made crowdsourcing platforms, he can help quickly identify new outbreaks and get some useful recommendations. In addition, this is almost 100% accuracy of data without the participation of a laboratory, which, for example, analysis of queries in search engines certainly can not give. But this method is bad because people may not find out about this resource in a timely manner.
Platform for USA: Flu near you. On the site you can anonymously talk about your well-being. The data is immediately visualized on a map so that others can go in and see in which regions there are sick people.
For 10 European countries: Influenzanet. Here you can fill out a questionnaire with questions about symptoms, geographical data. After that, every week, participants are reminded to report new symptoms and how their condition is changing. Everything is also anonymous. The data obtained are displayed on the charts and are updated every week.
Local News Monitoring
Regular monitoring of local news can really accelerate the state’s response to the epidemic. Consider several platforms that do this.
For example, canadian public resource GPHIN. By keywords, the information network analyzes data from various online news sources. It is available only by paid subscription and is usually used by international and non-profit organizations, states, and some private companies.
For the first time, GPHIN successfully helped detect an unusual virus in China at the end of 2002 3 months (!) Before the traditional monitoring system through some local newspaper in Guangdong Province.
You can not ignore the resource Worldometer. It displays world statistics on various topics (including healthcare) in real time. Analysts, developers, researchers and volunteers around the world collect data from reliable news reports. Despite the fact that the main source of information for the platform is still state data and laboratory-confirmed cases, they can respond faster than official messages. For example, to track information from social networks of someone from the authorities or from press conferences and immediately publish it.
Now they have a separate page by COVID-19. There you can find a form that allows you to report new cases. Which greatly speeds up the flow of new data. In profiles, some countries even have forecasts and data for certain regions.
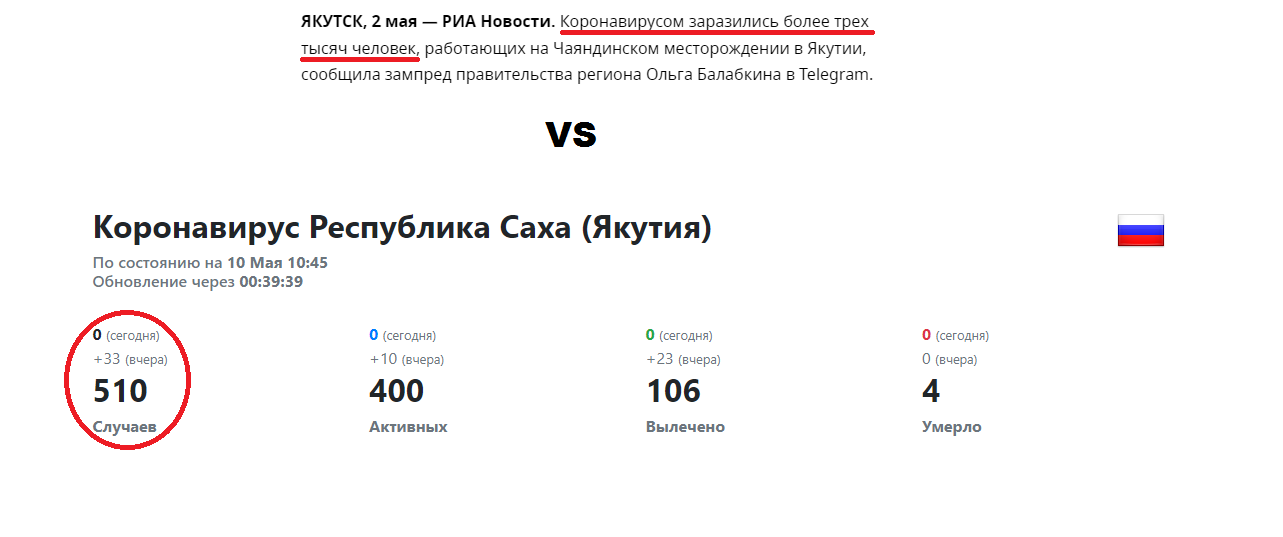
Analysis of local news from the point of view of OSINT helps not only to identify the epidemic, but also to avoid the spread of misinformation. Since it involves the processing of large amounts of data from various sources and verification of information found. Here is a recent example: appeared on the network informationthat in the Republic of Yakutia 3,500 people were infected with COVID-19 at some industrial facility. According to the official given as of May 10, there are slightly more than 500 infected in the whole republic. It would seem that both are open sources, but superimposing them on top of each other during a little reconnaissance made it possible to slightly adjust the picture of the epidemic in the region (or perhaps the whole country?)
Hybrid method
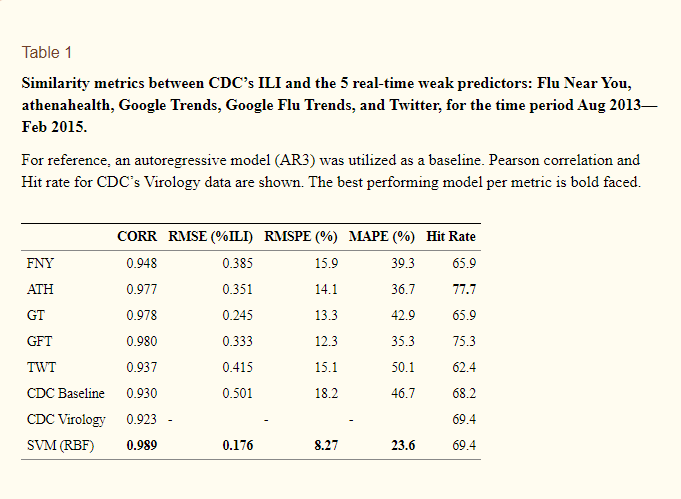
Some researchers propose combining outbreak detection through OSINT and traditional monitoring. For example, to combine in one system the results of queries on Google, the analysis of posts on social networks, crowdsourcing platforms and the data that people were treating some kind of disease from electronic medical records (they can be obtained, for example, using athenahealth) And this is a great option, because even if one of the methods gives incorrect or distorted data, it will not spoil the big picture.
In that example the researchers combined all the methods and compared with official data from the US Centers for Disease Control and Prevention (they have laboratory-confirmed cases). It turned out that the correlation of data from all sources with official data is much higher than if you use them separately.
What other tools are available for epidemic research using OSINT?
This is a resource that collects information over the network and not only checks it, immediately publishes it on its website and sends it to the mail to those who subscribe to them.
ProMED is open to any sources: media reports, official messages, data from local observers, etc. Before publication, a team of expert moderators checks the incoming information. By the way, ProMED is also available on Russian. This version covers only the Russian-speaking region of the post-Soviet countries.
Not the fastest way to detect epidemics, but, presumably, faster than a traditional monitoring system. A week before the official announcement of WHO, on December 30, 2020, ProMED learned of strange pneumonia from Weibo, a Chinese microblogging resource.
This is a system that uses algorithms to analyze tens of thousands of data sources: news portals, government posts, social networks, blogs. And all in order to identify and track new outbreaks. The resource immediately visualizes the received data in the form of a map. And in the fight against inaccuracies, they use artificial intelligence, which helps to get rid of repetitions and irrelevant information.
A striking example of the success of HealthMap is the recognition of the Ebola virus on March 14, 2014, 9 days before the official announcement from the Guinean health authorities.
How to deal with distortions in open source data
1. Open data are at the mercy of the respective companies (Google, Facebook, different platforms and sites). And these corporations can change algorithms when collecting information without any notice. Or delete or modify something in the collected data.
Solution: to accumulate the necessary data at home. Including – using ready-made tools such as web archive. So they can either be monitored in real time or analyzed in retrospect.
2. Lack of representativeness in the Internet. Data may indicate that there are more cases, for example, in the USA. In Africa, there may be even more. But since they have much less Internet coverage, it’s more difficult for them to identify themselves somehow. And the HealthMap and GPHIN platforms give better results in countries where there are more news portals and other media. Which also does not help the rapid recognition of epidemics in developing countries.
Solution: statistics will help here – look at where the data comes from and correlate with the number of people who live there, the number of people who have access to the network and extrapolate.
3. Coincidence with similar words with different meanings and in different contexts. If simple keywords are used to search without complex filtering, then there is a chance to get the wrong information. 2007 US Google trends mistakenly revealed cholera epidemic. And it’s just that Oprah Winfrey chose the novel “Love during Cholera” for her book club and therefore there was a sharp surge in requests for the word “cholera”.
Solution: we need automated semantic filtering – data separation with keywords that more accurately reflect the meaning of what we are looking for.
4. No confirmationthat people who are looking for something or writing something are really infected and sick. This can be solved using the hybrid method, which we talked about above, or you can rely on big data + the law of large numbers, which collectively neutralize the negative effect.
What’s Next: Improving OSINT Outbreak Detection Efficiency
At a minimum, the data that users leave publicly available should be available for analysis by health authorities and others who want to know more and faster about the epidemiological situation in the country and in the world. Indeed, not all platforms provide the ability to upload data or even somehow analyze what is happening through OSINT.
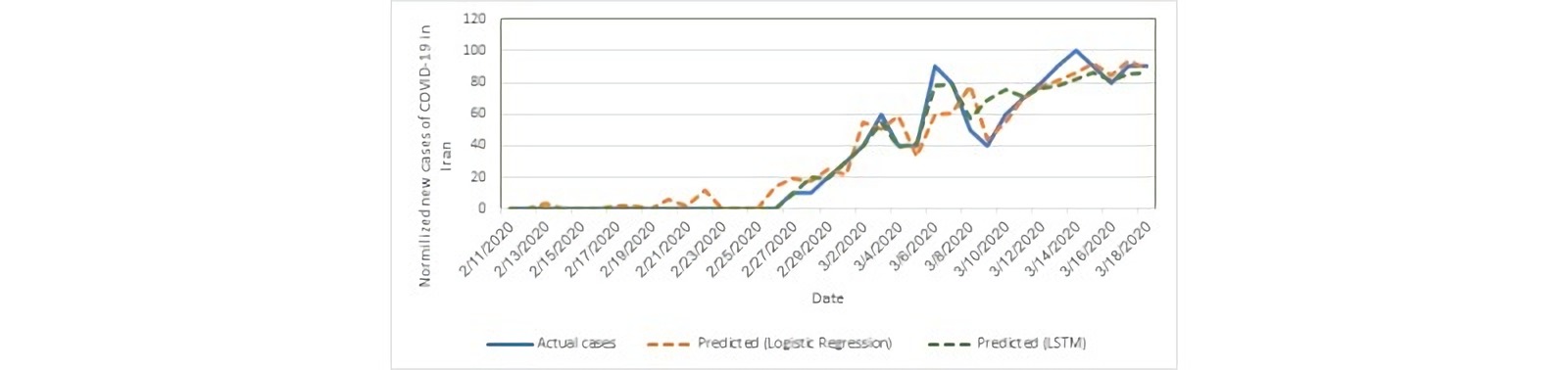
Some researchers are trying to “tie” machine learning tools to such analytics. For example, in Iran carried out experiment with long-term short-term memory (LSTM) and the COVID-19 pandemic. They used data from Google Trends and could very well predict the number of new cases. The graph below shows how the actual number of cases correlates with LSTM prediction. Researchers note that if there were more data for training, then the results would be more accurate.
Deep learning try to use to predict the number of people infected with HIV. For example, in China, for the experiment, they took official data for 2005-2016 for the Guangxi Autonomous Region and, using different models (including LSTM), they tried to predict the number of infected for 2015-2016. Researchers compared the results with real data, and long-term short-term memory gave the most accurate predictions.
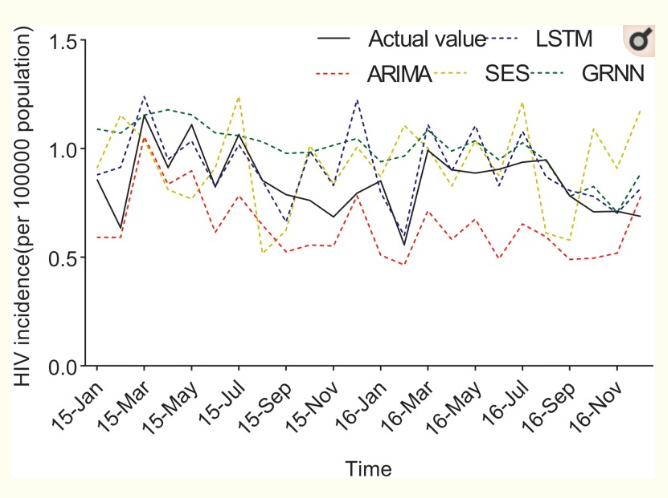
To develop tools based on deep learning, you need a lot of data. And now there is a tendency, on the contrary, to leave as little of your information on the Internet as possible, to protect your privacy. Nevertheless, as practice has shown, in order to successfully apply the OSINT methods in the study of any problem, it is enough to be able to quickly find relevant sources in the public domain and have in its arsenal several techniques for their effective analysis.





