how instant flight search works
Hello everyone, I work for the Dyninno group of companies. This is a large international holding that provides services and products in the field of tourism, finance, entertainment and technology in 50 countries. The basis and the most significant part of our business is the sale of air tickets. Therefore, the speed and the maximum number of the most relevant search results for customers is our cornerstone. And today I propose to look at how our search works from the inside.
This material will be of interest to those who deal with scalable services written in Go and deployed in Kubernetes. I’ll talk about integrating our own services with Amazon SQS and databases – both internal and external.
From a business process point of view, we provide our travel agents with technical tools and data to facilitate and speed up the process of selling air tickets over the phone. There is more than one system behind this, only about a dozen systems and services are involved in the process of searching for flights, each of which is responsible for its small part in the common cause. But the heart of it all is the FLST (Flight Search Tool) system, which I would like to talk about in more detail today.

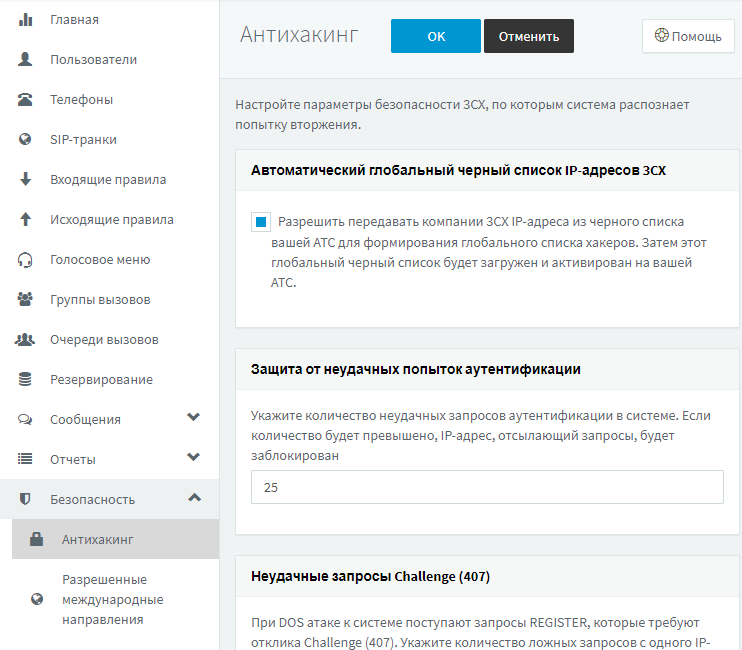
The process of searching for flight options in FLST
FLST is a set of scalable services deployed in Kubernetes, whose task is to find all possible flight options as quickly as possible. A flight search request usually consists of basic information: date, departure and destination points, number of passengers, class (business / economy). One incoming flight search request (we call it a logical search) usually generates about 20 top-level configurations (or physical searches). The number of such configurations depends on where (i.e. in which booking providers) and under what conditions our services will search for all possible options, but let’s talk about everything in order.
So, each request is processed like this:
Step 1. When we receive a search request, we put it in a queue (we use Amazon SQS). The first service that starts working with an incoming request is the Validator. The Validator checks the incoming request against its parameters, and if everything is in order, the request, based on the rules, is transformed into a series of higher-order configurations. These configurations, as mentioned above, contain all the necessary information, on the basis of which you can send a request to the global booking provider. We use MariaDb to store the rules. These rules are formed through a separate interface with the help of our experts from business units and sellers: they determine which airlines we work with and under what conditions, which destinations we can sell tickets to, where it is best to find them, what exceptions can be.
Step 2 Once the Validator has created these configurations, it will pass them through KeyDB to the next service, the Throttling service. The main task of this service is to try to partially exclude, based on the accumulated statistics, configurations that did not perform very well in the past (for example, when certain airlines rarely provide flights to this destination, or the search for such options took too long in the past, etc. ). In order not to store gigabytes of statistics, Throttling uses a constantly updated Bloom filter. If a certain configuration does not pass through the filter, then we do not exclude it, but add it to the output in a small percentage of cases (about 10%).
The Bloom filter is a probabilistic data structure that allows you to determine whether an entity belongs to a set without having to store the entire set. In our case, it allows us to determine whether a similar request for air travel was considered unsatisfactory in the past. Our filter is based on statistics about all slow (more than 5 seconds) searches and searches that returned no results for one reason or another. We update it several times a week. The use of the Bloom filter allows, with a much smaller amount of stored information, to obtain almost the same result, with a small percentage of false positives, which is acceptable in our case.
Step 3 After processing by the Throttling service, at the output we have a ready list of physical searches (or rather their configurations) that we can already perform. These configurations are picked up by special processors (Search Workers) via KeyDB and sent to the international computer reservation system (GDS, Global Distribution System or global distribution system) in a format compatible with it. GDS are automated systems that act as a link between travel agencies and providers such as airlines, hotels, and other travel related services.
GDS returns a different number of proposals (flight options) for each request, usually no more than 300 (although not uncommonly more than 1000). This is the final stage, at which the services that sent us the initial request receive the search result (FLST either puts them either in Amazon SQS or sends them via a REST request). At this stage, we also evaluate the processing speed of each flight search request (according to our metrics, all searches that are processed for more than 5 seconds are considered slow) and use this information to update the bloom filter.
Further, this huge array of results is processed by our other internal systems. They form a list of the best (with the minimum transfer time or the cheapest) options that we are ready to offer the client, but this is no longer a task for FLST. At this stage, FLST has done its job – it found all possible flight options in the shortest possible time, and another system, no less interesting from a technological point of view, will be engaged in their optimization.
 works")
What is FLST made of?
FLST was originally a monolith written in PHP. But we quickly realized that it became difficult for PHP to ensure high performance of all related processes. There was a lack of simplicity in scalability and flexibility in organizing parallelism. Go is the best fit for this, and we quickly became convinced of this.
Validator, Throttling and Search Workers are our services written in Go and deployed on Kubernetes clusters. The service architecture and interaction through Amazon SQS and KeyDb allow us to scale in much larger volumes, and, if necessary, work on the performance of a single link in the entire chain.
All of our services scale both horizontally (based on metrics) and vertically (adding resources as we see fit). For example, there are a little less than 20 search services (pods) by default, but their number increases to almost a hundred during peak periods. Each search service has limits on how many searches it can do in parallel, this is a controllable setting based on current CPU/RAM resources. Accordingly, when the number of incoming requests for logical searches increases, more services are automatically launched to process them.
An important point for each service is monitoring – we collect a huge amount of metrics presented in several panels in Grafana, and also collect logs of the ELK search process. For compilation and dockerization, we use GitLab CI pipelines, and we deploy all systems through ArgoCD, which runs services in Kubernetes.
Conclusions and plans
The selection of the best air travel options, the sale of air tickets and related services are at the heart of the business of the Dyninno group of companies. Collaboration with business units provides synergy and allows us to better customize the delivery of relevant search results.
It is important for our agents to receive answers to their requests as soon as possible. Therefore, we are constantly working on optimizing our FLST system.
Vadim Mamontov, Tech Lead, Dynatech
https://github.com/kaytrance