How does he work

Almost a year ago Elon Musk offered make the Twitter recommendation algorithm public. The company recently posted the source code of its algorithm on GitHub.
In the article – their translation blog post with a description of the operation of the recommendation algorithm. It will fit:
anyone who wants to know how algorithms choose what to show you in the feed,
Data Scientist and ML Engineers as a unique source of insights into how a large recommender system works.
Twitter aims to show you the most relevant of what’s happening in the world at the moment. To do this, we need a recommendation algorithm that can extract from 500 million tweets daily the best ones that will eventually be shown in the “For You” (For You) section. In this article, we will explain how the algorithm selects tweets for your feed.
How do we choose tweets?
The foundation of Twitter recommendations is a set of algorithms and functions that extract hidden information from tweets, users, and interaction data. These models seek to answer important questions such as “What is the likelihood that you will interact with this user in the future?” or “Which communities stand out on Twitter and what tweets are popular in them?” Accurate answers to these questions lead to more relevant recommendations.
The recommendation system consists of three main stages:
Selection of candidates – extract the best tweets from different sources of recommendations.
Ranging those tweets using a machine learning model.
Application heuristics and filterssuch as filtering tweets from users you’ve blocked, NSFW content, and tweets you’ve already seen.
The service that is responsible for creating and providing the For You feed is called Home Mixer. Home Mixer is based on Product Mixer, our custom Scala platform that makes it easy to create a content feed. This service links various candidate sources, scoring functions, heuristics, and filters.
The diagram below illustrates the main components used to create a ribbon:
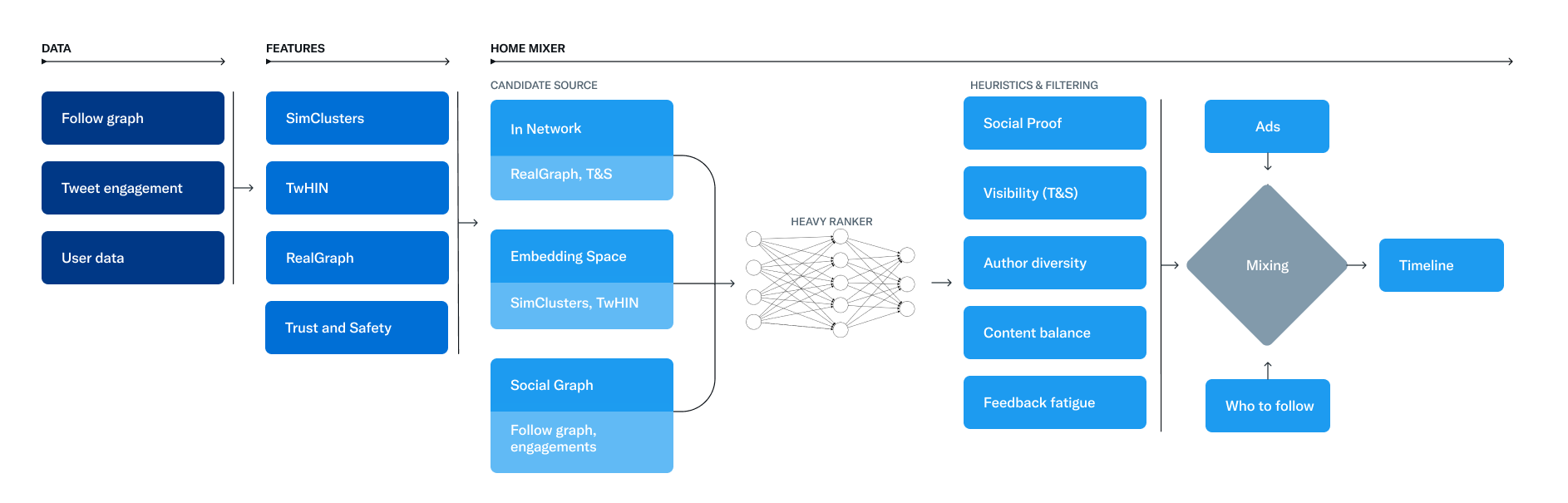
Let’s take a look at the key elements of this system, roughly in the order in which they are invoked during a single feed request. Let’s start by getting candidates from Candidate Sources.
Candidate Sources
Twitter has several candidate sources for getting fresh and relevant tweets. Through these sources, we are trying to extract the top 1500 tweets from hundreds of millions for each request. We find candidates from users you follow (In-Network), and from users you don’t follow (out-of-network). The For You feed consists of an average of 50% In-Network tweets and 50% Out-of-Network tweets, although this percentage may vary from user to user.
Source In-Network
In-Network is the largest source of candidates. It provides tweets from users you follow. Using a logistic regression model, these tweets are sorted by their relevance. The best tweets are then sent to the next stage.
The most important component in In-Network tweet ranking is Real Graph. Real Graph is a model that predicts the likelihood of an interaction between two users. The higher the Real Graph score between you and the tweeter, the more we will include their tweets.
The In-Network source has been recently redesigned. We stopped using the Fanout Service, a 12 year old service that provided cached tweets for every user. We are also reworking the logistic regression ranking model, which was last updated and trained several years ago!
Out-of-Network Sources
Finding relevant tweets outside the user’s network is a more difficult problem: How can we determine if certain Tweets are relevant to you if you are not following the author? Twitter uses two approaches to solve this problem.
1 Social Graph
The first approach analyzes the likes of the people you follow or those who have similar interests to you.
We walk through the interactions and subscriptions graph to answer the following questions:
What tweets have been recently liked by people I follow?
Who likes the same tweets as me and what else have they liked recently?
We create candidates based on the answers to these questions and rank the resulting tweets using a logistic regression model. Such graph traversals are critical to our recommendations. For this we have developed GraphJet, a graph processing engine that maintains a real-time graph of interactions between users and tweets. While this approach has proven to be useful (accounting for about 15% of home page feed tweets), approaches based on the embedding space contribute more.
2 Embedding Spaces
Embedding approaches want to answer a more general question about content similarity: What tweets and users are similar to my interests?
Embedding is a numerical representation of the interests of users and the content of tweets. From these, we can calculate the similarity between any two users, tweets, or user-tweet pairs in that embedding space. This similarity can be used as a substitute for relevance, provided the embeddings are accurate enough.
One of the most useful embedding spaces on Twitter is SimClusters. SimClusters find communities around influential users (influencers) using custom matrix decomposition algorithm. There are 145,000 communities that are updated every three weeks. Users and Tweets can belong to multiple communities. Communities range in size from a few thousand users for individual groups of friends to hundreds of millions of users for news or pop culture. Here are some of the biggest communities:
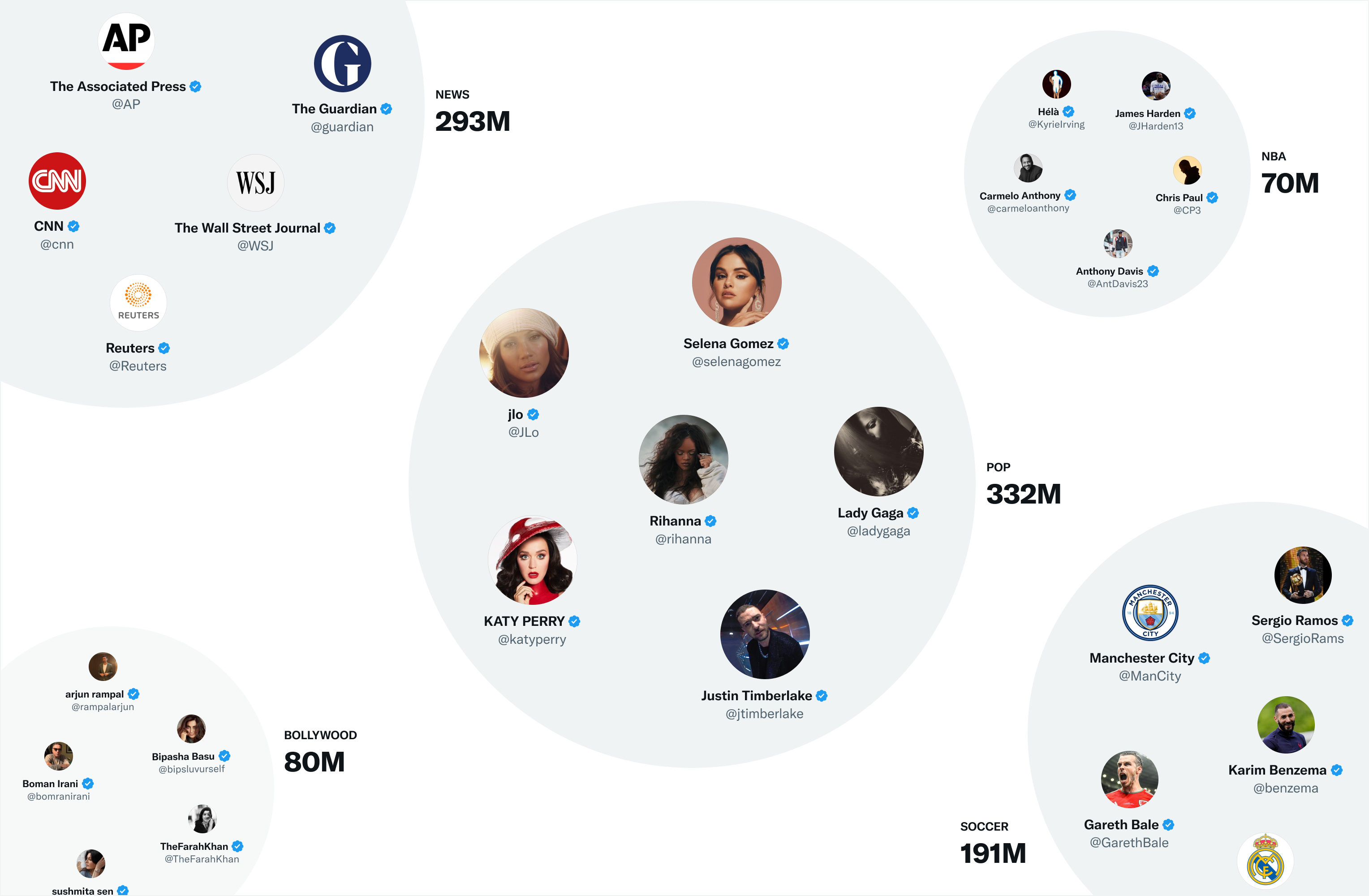
We include a tweet in a community based on its current popularity in that community. The more users in the community like it, the more that tweet will be associated with that community.
Ranging
At this stage, we have ~1500 potentially relevant candidates. The next step is to speed up each candidate for compliance with your particular feed. Here, all candidates are treated the same, regardless of the source.
Ranking is achieved using a neural network with ~48 million parameters that continuously learns from interaction with tweets. It optimizes positive feedback (like likes, retweets and replies). This ranking engine considers thousands of features and produces ten labels. Thus, each tweet receives a composite score, where each label indicates the likelihood of interaction. We rank tweets based on these ratings.
Heuristics, filters and additional functions
The next step is to apply heuristics and filters to improve the quality of the product. Additional features interact with each other to create a balanced and diverse feed. Here are some examples:
Visibility filtering: Filter tweets based on their content and your preferences. For example, remove tweets from accounts that you have blocked.
Variety of authors: Avoid long sequences of tweets from the same author.
Content balance: Balancing In-Network and Out-of-Network tweets.
Accounting for negative feedback: Reduce the rate of tweets close to those where you gave negative feedback.
Confirmation from the environment: Exclude tweets from users over the 2nd link level. That is, it is guaranteed that among your subscriptions there is a user who interacted with this tweet or is following its author.
Correspondence: Add the original tweet to the reply.
Edited tweets: Detect tweets that are currently out of date on the device and replace them with edited versions.
Enrichment and data transfer
At this point, Home Mixer receives a set of tweets ready to be sent to the device. Tweets are mixed with other content, such as ads, subscription recommendations, and tips, which are then returned to the device for display.
The above pipeline runs about 5 billion times a day and takes an average of 1.5 seconds to complete. However, a single pipeline run requires 220 seconds of CPU time – almost 150 times more than the delay you see in the application.

The main goal of the open source project is to provide you, our users, with complete transparency about how our systems work. We have made the recommendation code available for a more detailed acquaintance with our algorithm, it can be viewed Here (And Here). We are also working on providing more transparency on other features within our app. Some of the planned new developments include:
The best analytics platform for content creators with more insights into reach and engagement.
Greater transparency about any security labels applied to your tweets or accounts.
Greater visibility into why tweets appear in your feed.
If you want to read more about Data Science, machine learning and more, subscribe to my telegram channel.




