How does computer vision work?
Self-driving cars quietly go around cars and brake in front of pedestrians, CCTV cameras on the streets recognize our faces, and vacuum cleaners mark on the map where the slippers lie – all these are not miracles. This is happening right now. And all thanks to computer vision.
Therefore, today we will analyze how computer vision works, how it differs from human vision, and how can it be useful to us, people?
In order to navigate well in space, a person needs eyes to see, a brain to process this information, and intelligence to understand what you see. With computer or, even more correctly, machine vision, the same story. In order for the computer to understand what it sees, you need to go through 3 stages:
- We need to get the image somehow
- We need to process it
- And only then analyze

Let’s go through all the steps and check how they are implemented. Today we will understand how robots see this world, and will help us with this robotic vacuum cleaner, which is stuffed with modern computer vision technologies.
Stage 1. Image acquisition
At the beginning, the computer needs to see something. This requires different kinds of sensors. How many sensors and how complex they should be depends on the task. For simple tasks such as motion detection or object recognition in a frame, a simple camera or even an infrared sensor is sufficient.
There are two chambers in our vacuum cleaner, they are located in the front. But, for example, additional sensors will be needed for orientation in three-dimensional space. In particular, the 3D sensor. Here it is also located on top. But what is this sensor?
LiDAR
In general, there is a little confusion with the names of 3D sensors, the same thing is often called by different words.
This thing on top is called LDS or Laser Distance Sensor, in English – Laser Distance Sensor. You may have noticed similar sensors on the roofs of unmanned unmanned vehicles. This is not a flasher, it is a laser distance sensor, the same as on a robot vacuum cleaner.
But in the world of drones, such a sensor is usually called a lidar – LIDAR – Light Detection and Ranging. Yes, just like the new iPhones and iPad Pros.


But in Android smartphones, instead of lidars, the term ToF camera is used: ToF – Time-of-flight.
But whatever you call it, all these sensors work according to the same principle. They emit light and measure how long it will take for him to come back. That is, just like a radar, only light is used instead of radio waves.
There are small nuances in the types of such sensors, but the meaning of the technology does not change from this. Therefore, purely because of the consonance with the radar, I like the name LiDAR the most, so we will call this sensor.
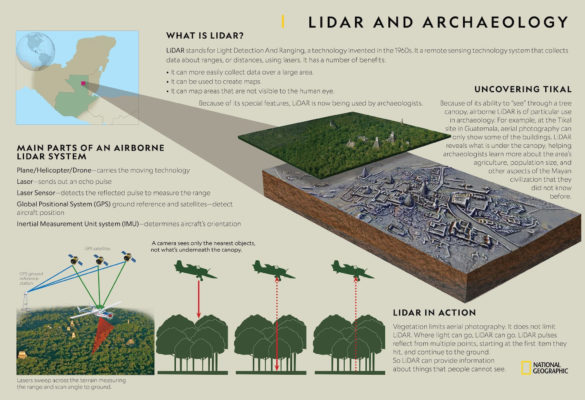
By the way, lidars are used not only in navigation tasks. Thanks to lidars, a real revolution in archeology is now taking place. Archaeologists scan an area from an airplane using a lidar, and then clear the landscape data from trees. And this allows you to find ancient cities hidden from human eyes!


Also, in addition to static lidars aimed in one direction, there are rotating lidars that allow you to scan the space around you 360 degrees. Such lidars are used in unmanned vehicles, and in this robotic vacuum cleaner.

Even 8 years ago, such sensors cost some incredible money, under 100 thousand dollars. And now a small drone can safely drive around your house.

Lidar in a vacuum cleaner
Okay, the lidar is being used to build a room map and this is not a new story. We saw such technology 3-4 years ago.
Thanks to the lidar and the built map, the vacuum cleaner does not drive randomly like a screensaver in Windows, knocking on corners, but accurately driving through the entire area (models without lidars usually ride strangely).
But inside the vacuum cleaner there is, for a moment, an eight-core Qualcomm Snapdragon 625 (Qualcomm APQ8053), so he has enough brains not only to build a map, but also to navigate by it.
Moreover, the vacuum cleaner can store up to four cards in memory and recognizes floors. This significantly speeds up cleaning. Therefore, when moving from floor to floor, the vacuum cleaner can understand this and does not waste time to rebuild the map.

Also, each of the 4 cards can be divided into 10 special zones. For which you can set your own cleaning parameters: suction power (up to 2500 Pa), the number of passes, etc. And somewhere it is possible to prohibit driving altogether. You can even choose between dry and wet cleaning for different areas. True, for this you do not need to connect / disconnect a separate water tank. And all this became possible thanks to the lidar.
Nevertheless, the technology has some disadvantages – very sparse data. The space is scanned with lines. Large car radars have a resolution of 64 to 128 lines. Plus, lidar has a dead zone. If the lidar is on the roof, then it does not see what is happening in a sufficiently large radius around it.
Also, in a robot vacuum cleaner, the lidar scans the space with just one beam. Therefore, all he sees is a thin line at a height of about 9-10 centimeters from the floor. This allows him to determine where the walls and furniture are, but he does not see what is lying on the floor.
Two cameras

Therefore, to correct this lidar defect. both cars and vacuum cleaners are equipped with additional cameras. There are two cameras at once, and they provide stereoscopic vision. Yes, yes, the vacuum cleaner has everything like humans – two eyes.
Two cameras, firstly, allow you to remove the dead zone in front of the vacuum cleaner. And secondly, they allow you to accurately determine the distance to objects lying on the floor.
This allows the vacuum cleaner to detect objects at least 5 cm wide and 3 cm high and go around them.
Stage 2. Processing
So, we got enough data from various sensors. Therefore, we move on to the second stage of computer vision – processing.
We receive data from the lidar in the form of a three-dimensional cloud of points, which in fact does not need additional processing.
How to get stereo from two cameras is also clear – the difference between the images taken at slightly different angles is calculated and this is how the depth map is built. It is not difficult.

But combining data from different sensors is not a trivial task.
For example, a vacuum cleaner has found an object on the floor. Next, he needs to understand exactly where he is on the map built using the lidar. And you also need to assume what dimensions it has in projection on one side. That is, we need to place the object in a certain volumetric cube of the correct size.


This problem can be solved in different ways. One of the ways is called a “truncated pyramid”. Objects are first detected on the camera. Then these objects are placed in a cone, and the volume of this cone is calculated by the neural network.
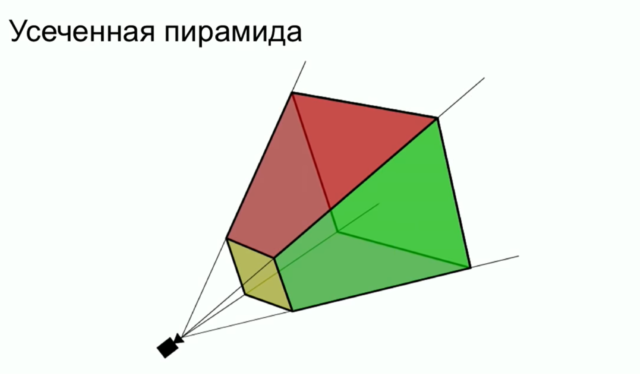
Therefore, even a seemingly trivial task requires serious calculations and is solved using neural networks.
And since we started talking about neural networks, it means that we have already entered the third stage of computer vision – analysis.
Stage 3. Analysis
Neural networks are mainly responsible for the recognition, segmentation and classification of objects in the image in the modern world. We even made a detailed video on how it works, take a look.
In short, a neural network is such a large number of interconnected equations. By loading any data into the neural network, you will definitely get some kind of answer.
But, for example, if you constantly upload pictures of cats to the neural network, and tell her that the answer should be – a cat. At some point, the neural network stops making mistakes on the training set. And then they begin to show her new unfamiliar images and if she also accurately identifies cats on them, the neural network is trained.
Further, the neural network is optimized so that it becomes smaller, works quickly and does not consume a lot of resources. After that, it is ready for use.
Something similar happens to the neural connections in the human brain. When we learn or remember something, we repeat the same action several times. Neural connections in the brain are gradually strengthened and then it is easy for us!
For example, in this vacuum cleaner, the built-in NPU-module is responsible for the operation of the neural network. Still, inside the Snapdragon, the vacuum cleaner can afford it.
Neuronka is pre-trained to identify various household items: toys, slippers, socks, all sorts of extension cords, charging and even surprises from pets.
Object recognition takes place using the Google Tensorflow library. The algorithm learns itself and grows smarter from cleaning to cleaning.
Practice

In our robot vacuum cleaner, the recognition technology is called Reactive AI. We tested how well it works in practice.
The cool thing is that the vacuum cleaner marks all found objects on the map. Therefore, now, I do not promise, but this is possible, you will still find the lair of the missing socks.
You can always track what the vacuum cleaner sees through the proprietary application or Mi Home from Xiaomi. You can even just roll around the house, controlling the vacuum cleaner, and send voice messages to it. You can also control the vacuum cleaner through the Google Assistant or Alice. Everything is in Russian.
Recently, the brand has begun to be officially sold in Russia, so the devices are completely localized.
Inside, by the way, there is a 5200 mAh battery, which can withstand up to 3 hours of cleaning.
Outcomes

Guys, you yourself saw everything. However, it is worth noting that while correct object recognition works only if you run the vacuum cleaner through a special application. And this is a nuance, since it is not yet available in the Play Market Russia. But within a few months it will appear.





