How ABLYY NLP Technologies Learn to Monitor News and Manage Risks
 The range of tasks that can be solved using ABBYY technologies has replenished with another interesting opportunity. We trained our engine in the work of a bank underwriter – a person who catches events on counterparties from a gigantic stream of news and assesses risks.
The range of tasks that can be solved using ABBYY technologies has replenished with another interesting opportunity. We trained our engine in the work of a bank underwriter – a person who catches events on counterparties from a gigantic stream of news and assesses risks.Now, such systems based on ABBYY technologies are already used by several large Russian banks. We want to talk about the nuances of implementing this solution – rather nontrivial and unexpected challenges that our ontologists have faced.
Curb the news flow
To succeed, a bank needs to know exactly who it is dealing with and respond quickly to important changes in the life of its counterparties. Especially when these are other banks or large corporate clients – IT companies, agricultural enterprises and others. For this, most Russian banks have special experts – underwriters. They analyze information from various sources, including news reports, for risk factors for the bank. It is necessary not only to read the news, but also to evaluate how it will affect the bank and its customers.
Risk factors may vary:
- bankruptcy,
- shareholders conflict
- Changes in ownership or management structure,
- facts of fraud, threat of loss of business by a client,
- information about claims and unscheduled inspections by regulatory agencies,
- the presence of claims
- economic crisis in the country, natural disasters and other force majeure circumstances
- and other risk factors.
If the underwriter identifies a risk factor, then in the long term cooperation with such a counterparty can bring problems to the bank, up to the trial. And the probability of a negative outcome is important to find out as quickly as possible. Why is it not so simple? In the news, not only the mention of counterparties is important, but also the context. You need to understand what is the relationship of a person or company with the factors that the bank relates to risk sources.
Meanwhile, the news flow, especially considering not only federal but also regional media, is huge and continues to grow. Medialogy alone, a news monitoring service, aggregates content from 52 thousand sources. According to Roskomnadzor, as of September 2019 in the register of Russian media was registered more than 67 thousand active media. A person is physically unable to quickly read all the news, even if it is only a topic of interest to him. So banks have to either constantly replenish the staff of underwriters, or look for an alternative solution in the field of information technology.
Decision options
The most obvious way is to narrow the flow of messages through paid subscriptions to closed news feeds on various topics. Such tapes are offered by Interfax, Prime, Thomson Reuters, Bloomberg and other news agencies. The news in them is already partially structured: there are tags with company names, key persons involved in the news. But this does not solve the problem completely: work with the context still rests with the underwriters.
Many existing media monitoring systems in companies work by searching for keywords in the text. This approach gives a lot of informational “noise” and does not work without additional tricks in the form of filters. Completeness and accuracy in the scenario with keywords leave much to be desired, because:
- The keyword and its cognate variations may be mentioned in the text, but not relevant. For example, a company may be listed in a historical reference that is not directly related to the message.
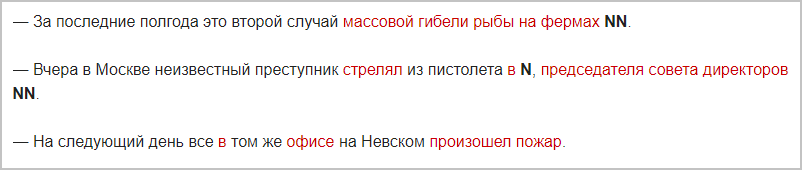
- In the news, it’s important not only to mention counterparties, but also the context. You need to understand what is the relationship of a person or company with the factors that the bank relates to risk sources. If you look at examples of risk factors in the message texts, you can see how many potentially significant news can be missed when searching by keywords. So, the phrase “shareholder conflict” is not always mentioned in the news. Meanwhile, if you look at the example below, for the underwriter the conflict or its potential is obvious:

In addition, there are many other negative news that must be considered when analyzing the company’s activities. However, they do not fall into one category and differ depending on the specifics of the client’s business:
You can quickly understand and analyze context in another way. It’s just the right time to recall our NLP technologies, which can automatically determine the type of content and extract meaningful entities from it.
First samples
So, one of the largest Russian banks decided to determine which of the two technologies would better cope with the task of finding risks. An intelligent document classifier determined risk factors based on the content of the news. The solution based on text analytics extracted the necessary data from the news. As a result, as it turned out, the best option is a symbiosis of two solutions: the classifier helped to narrow the number of documents that come from the tape, and removed completely irrelevant information, and then data extraction technologies were included in the work.
At the first stage – Proof of concept (POC) – the very possibility of using these tools to search for risks was tested. The customer chose one risk factor – a conflict situation. The technology was supposed to identify messages that spoke about the conflict of shareholders – individuals or legal entities, top managers of the bank or about the conflict of the bank with regulatory agencies. ABBYY Onto-Engineers created a trial model for the development of which a selection of 1000 news was used. She extracted the text of the conflict, the date of the news and a list of its participants. The model proved the viability of the proposed approach: at the POC stage, on the control sample provided by one of the banks (news that were not used for development), the following results were obtained from 50 documents:
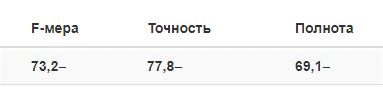
Completeness determines what percentage of the factors in the sample we found, and accuracy – what percentage of the factors that we have identified are indeed such. F-measure represents the harmonic mean between accuracy and completeness.
After the successful completion of the POC, a pilot was launched, and he showed good results. Below are the results of the pilot in one of our projects. Compared to searching for news by keywords, the ABLYY NLP module can filter three times as many irrelevant messages. This means that the risk manager will need to analyze three times less news.
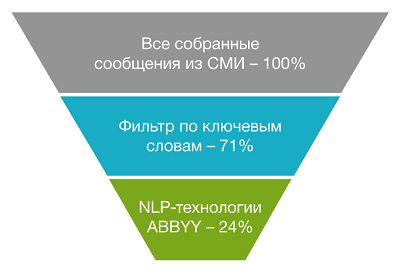
Improving the result
In the process of developing models, ontologists are guided by the results of regular self-tests, in which all discrepancies between the target and the obtained values are recorded. To build such reports, the news was marked in accordance with the instructions provided by the customer. Marked xml files containing target values were compared with xml files obtained as a result of using the current version of the ontomodel. The results of autotests provide both summary information containing quality indicators for the analysis of the entire news collection, as well as private information for each extracted object and document separately. So you can evaluate how the accuracy of the model in dynamics increases.
Here is an example of such a table:
Model results can also be measured using Accuracy Metric, a derivative of completeness and accuracy:
Accuracy metric can be called basic. It measures the number of correctly classified objects relative to the total number of all objects. Accuracy Metric has some disadvantages: it is not ideal for unbalanced classes, where there can be many instances of one class and few others.
This metric is used by another large bank, also our client. Accuracy Metric was 85%.
In the future, banks independently carried out the integration of ABBYY products, within which our model worked, and used them in their circuit. Our products are integrated with the banking risk management system: they transfer documents for analysis and collect the results.
How the system works
From a technical point of view, the system works like this: when the text gets processed into the ABBYY solution, its multi-stage linguistic analysis is performed. At the lexical-morphological stage, the simplest properties of words are determined: gender, number, case. Then, at the parsing stage, it is determined where the subject, predicate, how the words are related to each other. Knowing the syntax allows you to move on to defining semantics. For each word, its meaning is determined. On top of this linguistic analysis, the rules for extracting information that are developed by our ontologists are working. The ontomodel includes a description of the data structure to be obtained from customer documents, and rules that allow this data structure to be retrieved.
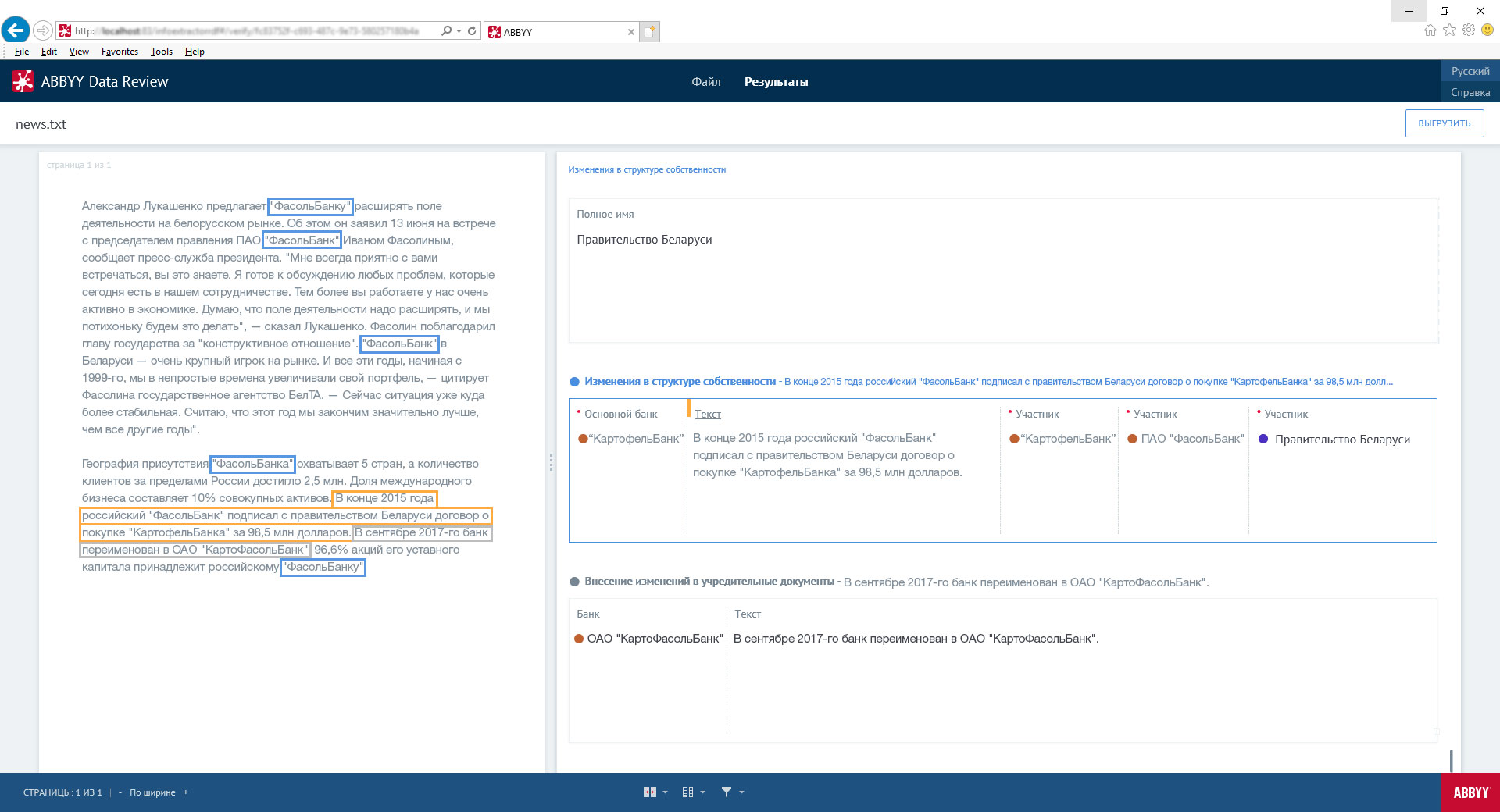
From the user’s point of view, everything looks as simple as possible. In your personal account, there are links to news on selected customers, in which the technology saw risks. Next to the link is the text of the risk factor itself. So the user does not need to read the whole news. Optionally, you can automatically receive links to news by mail.
After reviewing the text fragment, the underwriter himself decides what to do next with this information.
Unexpected difficulties
Risk is an abstract concept. This is a very specific professional field, and it is important to take into account the opinion of specialists who work with risks every day. Users of our customers can vote for the news and put a conditional “like”: whether the system correctly determined the presence of risk in the news or not.
In the process of debugging the system, we were faced with the fact that underwriters often interpret the meaning of the news and the presence of a risk factor in it. One user wants a certain type of news to appear in his feed, and another – considers such messages inconsequential. This problem is solved as follows: the bank collects from the underwriters a list of news, which experts gave different interpretations, and makes the final decision on the interpretation of a certain news: is there a risk factor in it or not. Modifications are made to the ontomodel depending on the feedback.
What if the news is in English?
Many Russian banks use sources such as Dow Jones, Bloomberg, Financial Times. One of the advantages of our approach to the development of ontomodels based on ABLYY NLP technologies was the quick adaptation of models developed for analyzing news in Russian for working with English texts. This requires debugging the model on the original English news.
Rate the results
Now underwriters can follow the news in real time, without having to read all 100,500 messages. In principle, you don’t even have to read the whole news where the system found a risk factor: the fragment with the most important (snippet) is highlighted in the program. In a couple of minutes you can automatically compile a report for one bank, highlight only one risk factor or several significant ones. With this approach, it’s harder to miss something important. Further, the underwriter can open the counterparty’s card and select the messages that he considers significant. Based on them, the credit rating of the company may be revised, the interest rate may be changed, or there may be a reason to contact the company management. These messages are passed on to the workflow system.
You may ask how much news the technology processes. It all depends on the news flow: in January and May, for example, there are traditionally fewer messages. One bank can check up to 2.5 million news items per month through our system. And this number is limited only by license and computing power.
By the way similar technologies can work not only in banks, but also in any companies that track a large flow of messages about competitors, customers, partners and read user reviews on social networks. For example, venture funds using NLP technologies can track information about promising start-ups in terms of potential investments, and government organizations – key news about what is happening in a particular region, what are the problems, who is responsible, etc. Moreover, you can analyze not only messages in the media, but also blogs and reviews on social networks.
And what tasks did you face when dealing with projects for processing unstructured documents for both banks and companies in other industries?