Cassandra. How not to die if you know only Oracle
My name is Misha Butrimov, I would like to talk a little about Cassandra. My story will be useful to those who have never encountered NoSQL databases – it has a lot of implementation features and pitfalls that you need to know about. And if, apart from Oracle or any other relational database, you have not seen anything, these things will save your life.
What is good about Cassandra? This is a NoSQL database designed without a single point of failure, which scales well. If you need to add a couple terabytes for any base, you just add nodes to the ring. Extend it to another data center? Add nodes to the cluster. Increase processed RPS? Add nodes to the cluster. The other way also works.

What else is she good at? It is to handle a lot of requests. But how much is how much? 10, 20, 30, 40 thousand requests per second – this is not much. 100 thousand requests per second for recording, too. There are companies that said they hold 2 million requests per second. Here they probably have to believe.
And in principle, Cassandra has one big difference from relational data – it does not look like them at all. And this is very important to remember.
Not everything that looks the same works the same
Once a colleague came to me and asked: “Here is the CQL Cassandra query language, and it has a select statement, it has where, it has and. I write letters and it doesn’t work. Why?”. If you treat Cassandra as a relational database, then this is the perfect way to end your life with brutal suicide. And I do not advocate, it is prohibited in Russia. You are just designing something wrong.
For example, a customer comes to us and says: “Let’s build a database for TV shows, or a database for a directory of recipes. We will have food dishes there or a list of TV shows and actors in it. ” We say joyfully: “Come on!”. These are two bytes to send, a couple of plates and everything is ready, everything will work very quickly, reliably. And everything is fine until the customers come and say that the housewives are also solving the inverse problem: they have a list of products and they want to know what dish they want to cook. You are dead.
That’s because Cassandra is a hybrid database: it is both key value and stores data in wide columns. Speaking in Java or Kotlin, it could be described like this:
Map
That is, a map, inside which there is also a sorted map. The first key to this map is the Row key or Partition key – the partition key. The second key, which is the key to the already sorted map, is the Clustering key.
To illustrate the distribution of the database, we draw three nodes. Now you need to understand how to decompose data into nodes. Because if we shove everything into one (by the way, there may be a thousand, two thousand, five – as many as you like), this is not really about distribution. Therefore, we need a mathematical function that will return a number. Just a number, a long int that will fall into some range. And we have one node will be responsible for one range, the second – for the second, n-th – for the n-th.

This number is taken using a hash function that applies just to what we call the Partition key. This is the column that is specified in the Primary key directive, and this is the column that will be the first and most basic map key. It determines which node gets which data. A table is created in Cassandra with almost the same syntax as in SQL:
CREATE TABLE users (
user_id uu id,
name text,
year int,
salary float,
PRIMARY KEY(user_id)
)
Primary key in this case consists of one column, and it is also a partition key.
How will users fall with us? Part will fall on one note, part on another, and part on the third. It turns out an ordinary hash table, it’s also a map, it’s also a dictionary in Python, it’s also a simple Key value structure, from which we can read all values, read and write by key.

Select: when allow filtering turns into full scan, or how not to do
Let’s write some select statement: select * from users where, userid = . It turns out, it seems, as in Oracle: we write select, we specify conditions and everything works, users get it. But if, for example, you select a user with a specific year of birth, Cassandra swears that she cannot fulfill the request. Because she does not know anything about how we distribute data on the year of birth – she has only one column specified as the key. Then she says: “Okay, I can still fulfill this request. Add allow filtering. ” We add a directive, everything works. And at that moment a terrible thing happens.
When we drive on test data, everything is fine. And when you fulfill the request in production, where, for example, we have 4 million records, then everything is not very good with us. Because allow filtering is a directive that allows Cassandra to collect all the data from this table from all nodes, all data centers (if there is a lot of them in this cluster), and only then filter it. This is an analogue of Full Scan, and hardly anyone is delighted with it.
If we only needed users by identifiers, this would suit us. But sometimes we need to write other queries and impose other restrictions on the selection. Therefore, we recall: we all have a map, which has a partition key, but inside it is a sorted map.
And she also has a key, which we call the Clustering Key. This key, which, in turn, consists of the columns that we select, with which Cassandra understands how her data is physically sorted and will lie on each node. That is, for some Partition key, the Clustering key will tell you exactly how to push the data into this tree, what place they will take there.
This is really a tree, a comparator is simply called there, into which we pass a certain set of columns in the form of an object, and it is also set in the form of an enumeration of columns.
CREATE TABLE users_by_year_salary_id (
user_id uuid,
name text,
year int,
salary float,
PRIMARY KEY((year), salary, user_id)
Pay attention to the Primary key directive, it has the first argument (in our case the year) is always the Partition key. It can consist of one or several columns, it doesn’t matter. If there are several columns, you need to remove it again in parentheses so that the language preprocessor understands that this is the Primary key, and behind it all the other columns – the Clustering key. In this case, they will be transmitted in the comparator in the order in which they go. That is, the first column is more significant, the second is less significant and so on. As we write for data classes, for example, equals fields: we list fields, and for them we write which are larger and which are smaller. In Cassandra, this is, relatively speaking, the data class field to which the equals written for it will be applied.
We set the sort, impose restrictions
It must be remembered that the sort order (decreasing, increasing, it doesn’t matter) is set at the same time that the key is created, and then you cannot change it later. It physically determines how the data will be sorted and how it will lie. If you need to change the Clustering key or the sort order, you will have to create a new table and pour data into it. With the existing one this will not work.
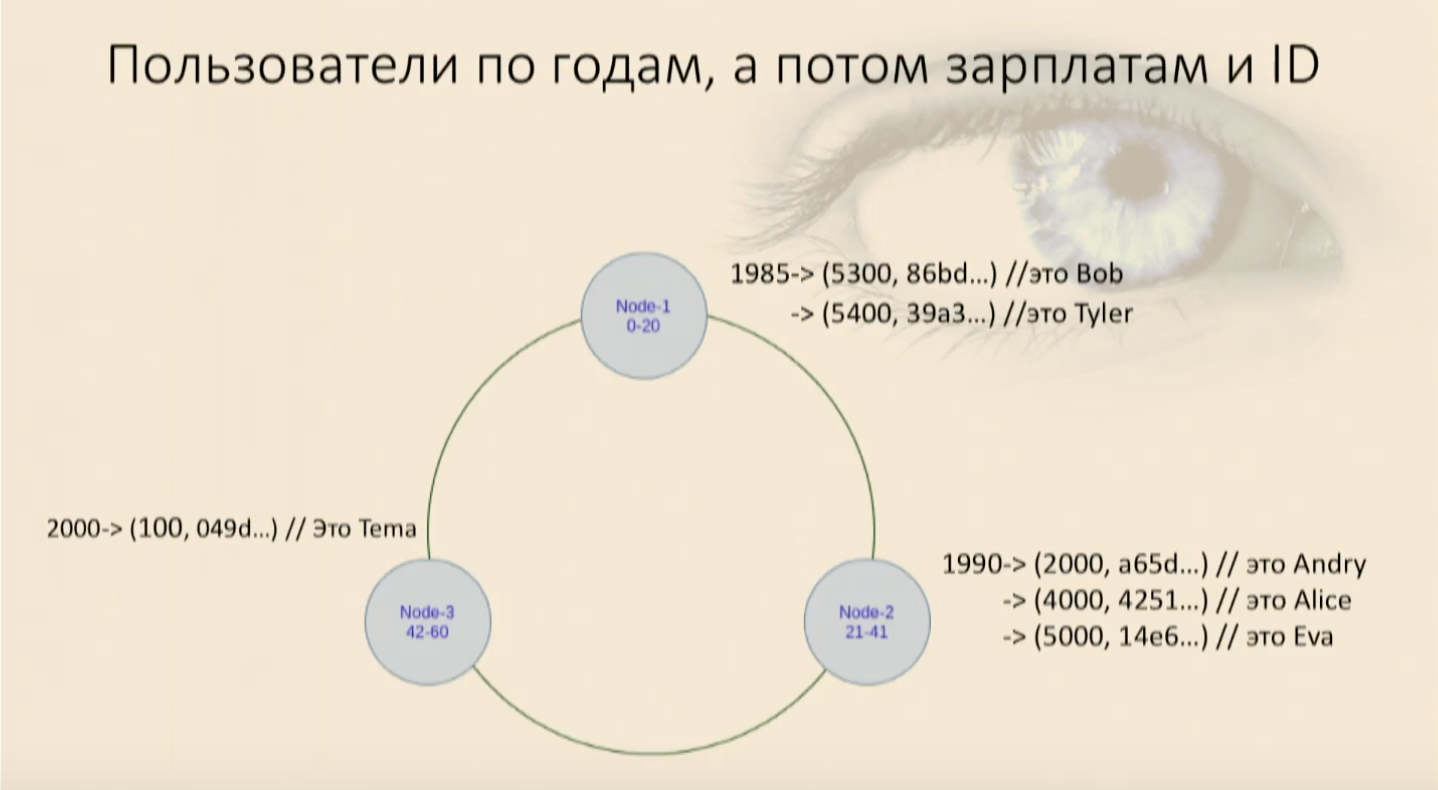
We filled our table with users and saw that they went into a ring first by year of birth, and then inside on each node by salary and by user ID. Now we can select by imposing restrictions.
Our working appears again where, and, and users get to us, and everything is fine again. But if we try to use only the Clustering key part, the less significant one, then Cassandra will swear right away that we can’t find in our map where this object has these fields for the comparator null, but this one that you just set – where it lies. I will have to pick up all the data from this node again and filter it. And this is an analogue of Full Scan within the node, this is bad.
In any incomprehensible situation, create a new table
If we want to be able to get users by ID or by age or by salary, what should we do? Nothing. Just use two tables. If you need to get users in three different ways – there will be three tables. Gone are the days when we saved space on the screw. This is the cheapest resource. It costs much less than response time, which can be fatal to the user. The user is much nicer to get something in a second than in 10 minutes.
We exchange excessive space, denormalized data for the ability to scale well, work reliably. Indeed, in fact, a cluster that consists of three data centers, each of which has five nodes, with an acceptable level of data storage (when nothing is lost for sure), is able to survive the death of one data center completely. And two more nodes in each of the two remaining. And only after that the problems begin. This is a pretty good backup, it costs a couple of unnecessary ssd-drives and processors. Therefore, in order to use Cassandra, which is never SQL, in which there are no relationships, no foreign keys, you need to know simple rules.
We design everything from the request. The main thing is not the data, but how the application is going to work with them. If he needs to receive different data in different ways or the same data in different ways, we must put them in the way that will be convenient for the application. Otherwise, we will fail in Full Scan and Cassandra will not give us any advantage.
Denormalizing data is the norm. Forget about normal forms, we no longer have relational databases. We put something 100 times, it will lie 100 times. It’s cheaper than stopping it anyway.
We select the keys for partitioning so that they are normally distributed. We do not need the hash from our keys to fall into one narrow range. That is, the year of birth in the example above is a bad example. Rather, it is good if our users are normally distributed by year of birth, and bad if we are talking about students of the 5th grade – it will not be very good to partition there.
Sorting is selected once during the creation of the Clustering Key. If you need to change it, you will have to overfill our table with a different key.
And the most important: if we need to collect the same data in 100 different ways, then we will have 100 different tables.