“Be Insight-Driven”: Advanced Analytics and Lifecycle Management of Machine Learning Models

What is the essence of the Insight-Driven approach
Many experts have been talking about the importance of Data-Driven for a long time, which, of course, is absolutely correct in general, because this approach involves making management decisions more effective by analyzing data, and not just intuition and personal experience of management. Forrester analysts note that companies that rely on data analysis in their activities grow on average 30% faster than competitors.
But we all understand that the company is moving forward not from the availability of data as such, but from the ability to work with them – that is, to find insights that can be monetized, and for which it is worth accumulating, processing and analyzing data. Therefore, we are talking specifically about the Insight-Driven approach, as a more advanced version of Data-Driven.
Most often, when it comes to working with data, most specialists primarily mean structured information within the company, however, not so long ago we talked about why the vast majority of business do not use about 80% of the potentially available data. Insight-Driven just creates the basis in order to supplement the picture with external unstructured information, as well as the results of data interpretation to search for implicit dependencies between them.
The promised link to a complete library of materials about data management, where there is the mentioned video about unused data.
DevOps + DataOps + ModelOps
Insight-Driven practices are based on DevOps, DataOps, and ModelOps. Let's talk about why a combination of these particular practices can ensure the full implementation of the approach.
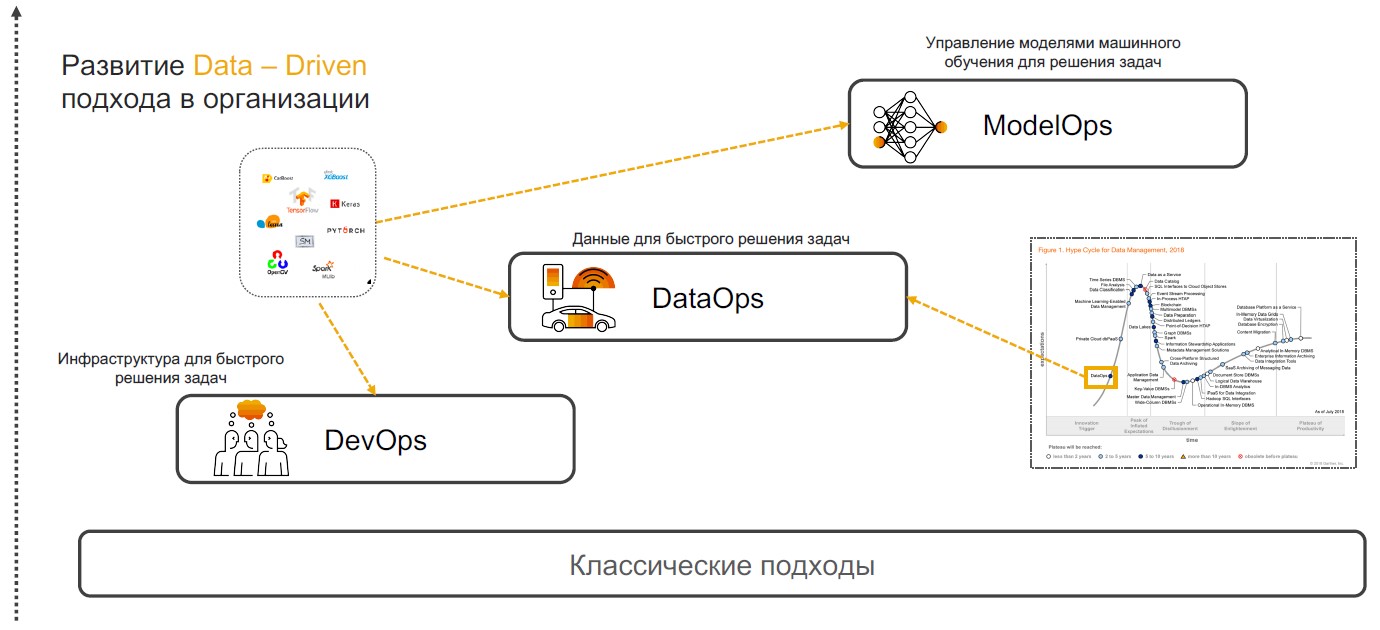
DevOps + DataOps. DevOps involves reducing the time of product release, its updates and minimizing the cost of further support through the use of tools for version control, continuous integration, testing and monitoring, release management. If we add to these practices an understanding of what data is inside the company, how to manage its format and structure, tag, monitor quality, transformation, aggregation and have the ability to quickly analyze and visualize, then we get DataOps. The focus of this approach is the implementation of scenarios using machine learning models that provide decision support, insight search and forecasting.
ModelOps. As soon as the company begins to actively use machine learning models, it becomes necessary to manage them, monitor quality metrics, retrain, compare, update and version. ModOps is a set of practices and approaches that simplify the life cycle management of such models. It is used by companies that deal with a large number of models in various areas of the business, for example, streaming services.
Implementing the Insight-Driven approach in a company is a non-trivial task. But for those who still would like to start working with him, we will tell you how to do this.
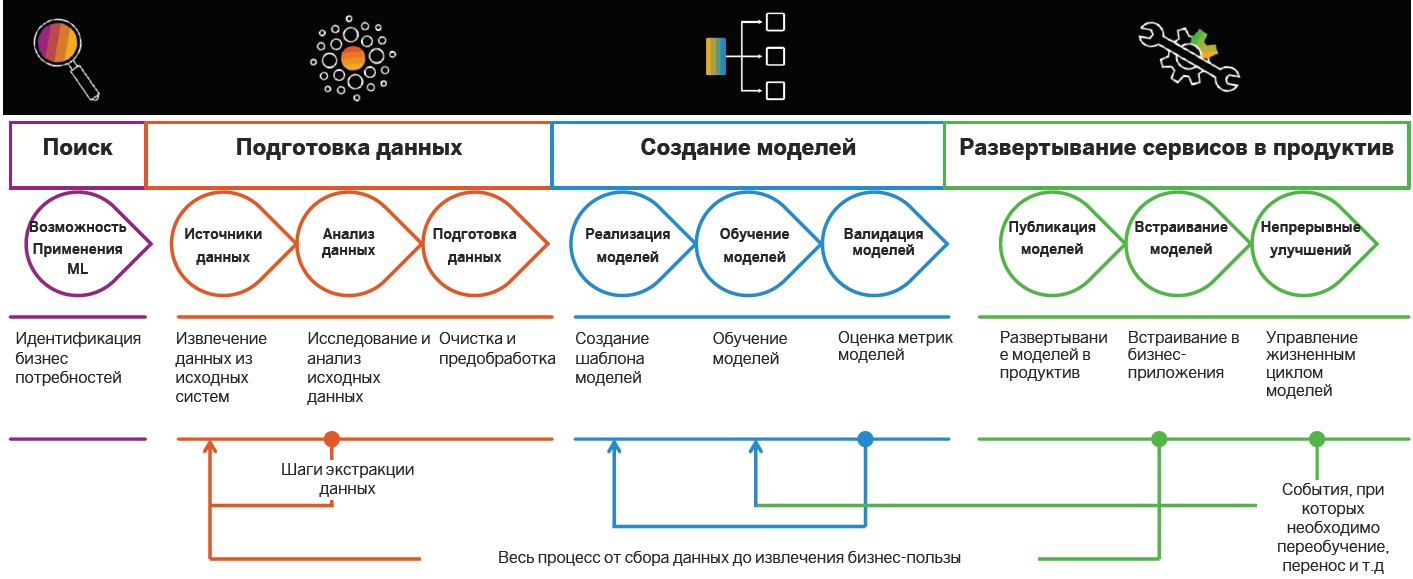
Search and data preparation
The implementation of Insight-Driven practices begins with the search and preparation of data. Later they are analyzed and used to build MO models, but cases are determined in advance, in which intelligent algorithms can be useful.
Task definition. At this stage, the company sets business goals, for example, increasing profit in the market. Next, business metrics are determined to achieve them, such as increasing the number of new customers, the size of the average check, and the percentage of conversion. So there are scenarios within which it is already possible to search for relevant data.
Sourcing and data analysis. When the goals and directions for data retrieval are defined, it is time to analyze the sources. This and the subsequent stages of developing intelligent scenarios that relate to preparation take 70–80% of the companies ’budgets for implementation. The fact is that the quality of the data set affects the accuracy of the designed machine learning models. But the necessary information is often "scattered" across various systems – it can lie in relational databases, such as MS SQL, Oracle, PostgreSQL, on the Hadoop platform and many other sources. And at this stage, you need to understand where the relevant data is and how to collect it.
Often, analysts unload and process everything manually, which greatly slows down the processes and increases the risk of errors. We at SAP offer our customers to implement a meta-system that connects to the right sources and collects data upon request.
So, you can catalog all tables, external pools with unstructured data and other sources – set tags (including hierarchical ones) and quickly collect relevant information. Conditionally, if information on a client lies in different databases, then it is enough to indicate these entities. The next time you need a “client data set”, you will choose a ready-made showcase.
When data sources are defined, you can go to data quality tracking and profiling. This operation is necessary to understand the number of gaps, unique values and verify the overall quality of the data. For all this, you can build dashboards with rules and track any changes.
Data transformation. The next step is direct work with data that should solve the tasks. To do this, the data is cleared: checked, deduplicated, filled in the gaps. This process can be simplified with flow-based programming. In this case, we are dealing with a sequence of operations – a pipeline. Its output can be sent to a graphical interface or other system for subsequent work. Here, the data handlers are assembled as a constructor (and depending on the scenario). This can be periodic or streaming processing, or a REST service.

The concept of flow-based programming is suitable for solving a wide range of tasks: from forecasting sales and assessing the quality of service to finding the reasons for the outflow of customers. There are two tools for searching and preparing data in SAP. The first – SAP Data Intelligence for data analysis professionals. Unlike similar platforms, this solution works with distributed data and does not require centralization – it provides a single environment for the implementation, publication, integration, scaling and support of models. The second tool is SAP Agile Data Preparation, a small data preparation service targeted at analysts and business users. It has a simple interface that helps to collect a data set, filter, process and map information. It can be published in a showcase for transferring Self-Service BI – self-service systems for creating analytical scenarios (they do not require in-depth knowledge in the field of data science).
Model creation
After preparation, it is the turn to create machine learning models. Here are distinguished: research, prototyping and productivity. The last stage includes the implementation of pipelines for training and application of models.
Research and prototyping. Currently there are many thematic frameworks and libraries available. The leaders in the frequency of use are TensorFlow and PyTorch, whose popularity over the past year has grown by 243%. The SAP platform allows you to use any of these frameworks and can be flexibly supplemented by libraries such as CatBoost from Yandex, LightGBM from Microsoft, scikit-learn and pandas. You can still use the HANA DataFrame in the hanaml library. This API mimics pandas, and HANA allows you to process large amounts of data using "lazy computing."
For prototyping models, we offer Jupyter Lab. This is an open source tool for data-science professionals. We built it into the SAP ecosystem, while expanding functionality. Jupyter Lab works in the Data Intelligence platform and due to the built-in sapdi library it can connect to any data sources connected in the previous steps, monitor experiments and quality metrics for their further analysis.
Separately, it should be noted that notebooks, datasets, training and inference pipelines, as well as services for deploying models should be consistent. To combine all these objects, use the ML script (versioned object).
Model training. There are two options for working with ML scripts. There are models that do not need to be trained at all. For example, in SAP Data Intelligence we offer face recognition systems, automatic translation, OCR (optical character recognition) and others. All of them work out of the box. On the other hand, there are those models that need to be trained and productive. This training can occur both in the Data Intelligence cluster itself and on external computing resources that are connected only for the duration of the calculations.
“Under the hood” in SAP Data Intelligence is the Kubernetes platform, so all operators are tied to docker containers. To work with the model, it is enough to describe the docker file and attach tags to it for the libraries and versions used.
Another way to create models is with AutoML. These are automated MO systems. Such tools are developed by H2O, Microsoft, Google, and others. They also work in this direction at MIT. But university engineers do not focus on embedding and productivity. SAP also has an AutoML system that focuses on fast results. She works in HANA and has direct access to the data – they do not need to be moved or modified anywhere. Now we are developing a solution that focuses on the quality of models – we will announce a release later.
Life cycle management. Conditions change, information becomes outdated, so the accuracy of MO models decreases over time. Accordingly, having accumulated new data, we can retrain the model and refine the results. For example, one major beverage producer uses consumer preference information in 200 different countries to retrain smart systems. The company takes into account people's tastes, the amount of sugar, the calorie content of drinks, and even the products that competing brands offer in the target markets. MO models automatically determine which of the hundreds of products the company will best accept in a given region.

Reusing Agent-Based Components in the SAP Data Hub
But versioning and updating models also needs to be done as fresh algorithms and hardware component updates are released. Their implementation can improve the accuracy and quality of the models used in the work.
Insight-Driven for Business Growth
The approach to managing the life cycle stages of machine learning models described above is, in fact, a universal framework that allows a company to become Insight-Driven and use work with data as a key driver for business growth. Organizations embodying this concept know more, grow faster, and, in our opinion, work much more interestingly in this cutting edge technology!
Learn more about building the Insight-Driven concept in our library of useful data management materials, where we have collected videos, useful brochures and trial accesses to SAP systems.