Application of microservice architecture in Big Data streaming
About architectural patterns
To begin with, let’s remember what microservices and monoliths are.
Microservices are a software design pattern using a set of small, independent and easily modifiable services. The main goal is to reduce the time to market for new products or functionality (Time to market or TTM). This goal is achieved by separating services based on the business context.
Monolith is a software design pattern where all components are combined into one unit of deployment.
About architectural models
Next, I want to clarify what I mean by Big Data streaming. In our company “MTS IT” in the Big Data Center, streaming data processing means the processing of data flow in real time. This can be the construction of analytical reports, for example, statistics on the congestion of metro stations or the shipment of data upon the occurrence of any events (triggers), for example, the entry of subscribers into a certain geofence.
Big Data means a huge load – several million events per second. Thus, we can come to the following definition: Big Data streaming processing systems are highly loaded systems used to build real-time analytics.
What is the main difference between such an architectural model, say, from the classical three-level model?
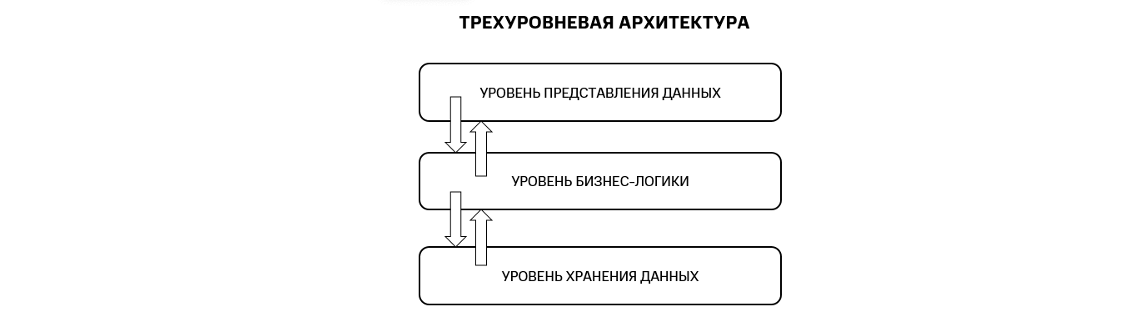
Figure 1. Three-tier architecture
In a three-tier architecture, data is not only provided to users, but can also be changed or deleted by them. This, in turn, leads to the need to store data in strict consistency. The user will be very disappointed if he credits himself with funds to the card through the mobile application, and then receives a message in the store that there are not enough funds on his account. This is an example of how data can be in an inconsistent state. Data consistency is achieved through transactions.
Organizing transactions in a distributed system, which inevitably results from a microservice architecture, is not an easy task. The easiest option is to move all transactional activity, if possible, into one service. But there is a possibility that more and more business logic will be added to it, and this violates the concept of microservices, and over time this service will resemble a monolith.
Another way is to use the two phase commit mechanism. Due to the network interaction between services, it is prone to failures, and the likelihood of failure increases with the addition of new services participating in a distributed transaction.
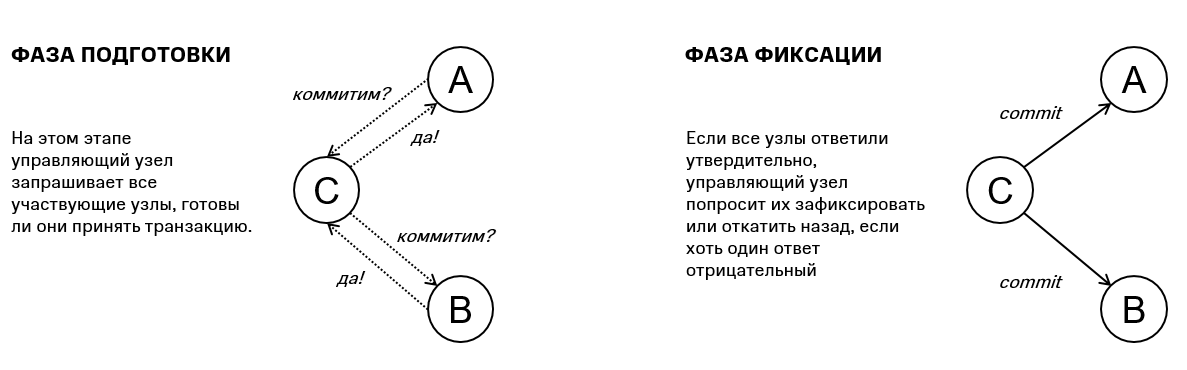
Figure 2. Two-phase commit
Another way is to apply saga pattern… Using this pattern, we move away from distributed transactions, but significantly increase the complexity of the implementation and increase the development time.
In the stream processing model, the received data is not modified by users, which means that we have enough data consistency in the end and there is no need to enter transactions into our system, which greatly complicate the development of distributed systems.
About an example of implementation
Let us consider the application of microservice architecture using the example of a small part of the MTS geoplatform, which is responsible for streaming data processing.
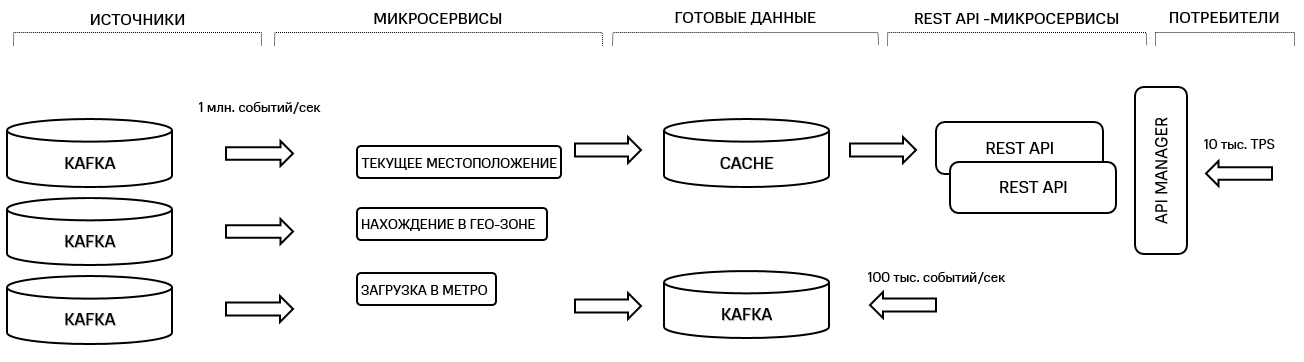
Figure 3. Microservice architecture of the geoplatform
There is a data source, in this case it is a Kafka cluster. Next comes a set of services, each of which implements a separate business case. For example, a service for determining the current location of a client, a service for monitoring the entrance of clients into a given geofence, or determining the workload of metro stations in real time. Then this data can be requested on demand, for example, through APIs, which are also divided into services by business cases, or read from a message queue, for example, Kafka.
Consider the advantages of using this architecture:
- Independently deploying and updating services. You can quickly release a new business feature or an entire service into commercial operation without fear of breaking the work of other services (short for TTM). This is especially true when processing big data. The large volume of incoming data and their diversity leads to the formation of a large number of new business cases and frequent changes in existing ones.
- Effective horizontal scaling. Some services are more loaded and demanding on resources, some are less. Knowing this information, we can individually scale each service, which is more efficient than scaling a service as part of a monolith.
- Services can be implemented using various programming languages, frameworks, etc. Again, it is very important in Big Data, where, due to the large number of business cases, many different teams are simultaneously working on one platform. Another significant plus is the ability to try out a new technology or framework “in battle” on a separate service.
- Low entry threshold for new developers. The small codebase is easy to figure out. Even if the service was written a long time ago and the quality of the code leaves much to be desired, this is not a problem either. Typically, a service can be rewritten from scratch in a few sprints.
- Team scaling. If the business context is immediately clear, i.e. how to divide the system into microservices, then, if resources are available, you can parallelize the development, significantly reduce the total time for the platform implementation.
Of course, there are also disadvantages:
- Distributed system. A system consisting of a dozen services becomes difficult to design and develop. Highly qualified architects and developers are required.
- Network interactions. Services communicate with each other over the network, and network connections are unreliable and prone to failure.
- Complexity of operation. A distributed system becomes difficult to deploy and maintain. Requires highly skilled devops and support services.
On the other hand, it would be possible not to divide the business case into different services and do everything in one monolith, like this:
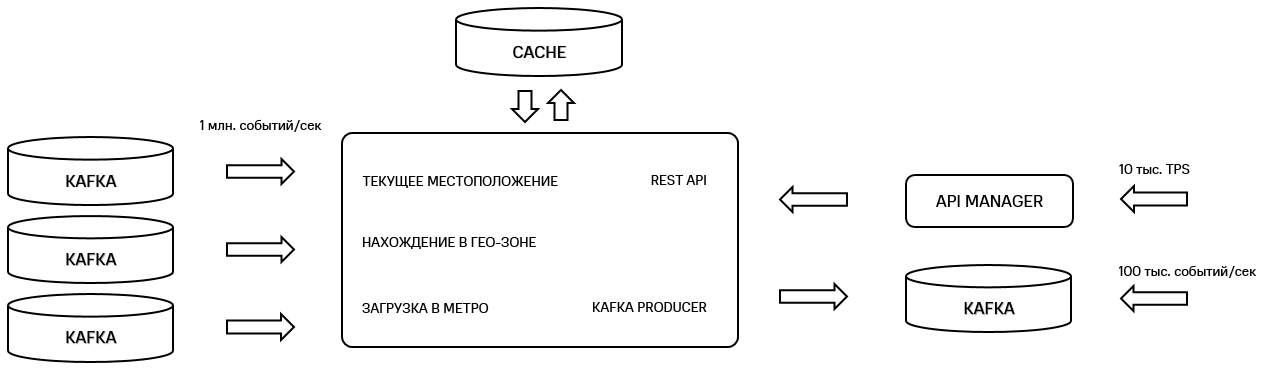
Figure 4. Monolithic architecture of the geoplatform
The benefits we will get:
- “Fast start”… Of course, a monolithic platform can be implemented more quickly.
- No networking between monolith modules. You don’t have to write a lot of code to handle exceptions that arise due to network problems. This greatly simplifies and speeds up development.
But there are also disadvantages, let’s list them:
- Decreased reliability. One small revision of one of the modules can theoretically “put” the entire platform on which we have several different cases for different customers.
- Strong connectedness. Some modules begin to use the methods of other modules in their implementation, as a result, in order to modify one module, several need to be changed. This makes development and testing very difficult. The time of launching new, even insignificantly functional, increases significantly.
- A large threshold for new developers to enter. It takes months for a developer to figure out a large codebase. And few people like to work with a lot of legacy code.
- It is difficult to introduce new technologies. If in the monolith you started using some kind of framework or technology, then later it will be very difficult to replace it with another one.
As a result, the monolith has more disadvantages than microservices. Many of you probably now think that most of the cons are contrived. After all, no one writes code like that, it’s a bad programming style, etc. And there is some truth in this reasoning, because everyone knows about GRASP patterns and SOLID principles… If you follow them, indeed, you can write a modular monolith in which each module has low coupling and high mesh. Thus, we will get rid of all the above listed disadvantages of the monolith.
I agree with this statement too, I myself have worked with large monoliths that were perfectly designed. But this does not always happen, since the code of a modular monolith is difficult to write, and most importantly, it is very difficult to maintain modularity. Especially when the monolith is getting bigger and more complex. Developers are always tempted to “finish” and reuse existing functionality a little. This can be controlled by code review. Problems can arise when key specialists leave the team.
In my practice, there was such a case when the team leader and the lead developer left a large modular monolith almost simultaneously. They have been writing this monolith for many years and making sure that it remains modular. They were quickly replaced, but the large codebase was not easy to figure out. Under pressure from business, a trial period and a simple desire to prove themselves, they began to write code “as they understood”, and the modular monolith quickly enough slipped into an ordinary monolith. All those disadvantages that I wrote about above returned to it. And this led to the stagnation of the project. The moral of the story is this: the departure of a key specialist most often leads to the death of a modular monolith.
About conclusions
Even if you work with streaming data processing, you shouldn’t throw everything and rewrite it on microservices. Microservice architecture is not a panacea. By solving some problems, we get others.
Let’s summarize. In what conditions should we think about using this or that architecture? And once again I want to note that all the recommendations, pros and cons apply only to streaming data processing systems.
When to consider using a microservice architecture:
- a large development team, or several teams;
- a team of highly qualified specialists;
- the business context is well described, at the initial stage there is an understanding of how to break the system into services;
- business requirements often change and you need to quickly bring these changes to market.
When not to use:
- the business context is poorly described, there is no understanding of how to divide the functionality into services;
- little time for implementation – if there are very tight deadlines for implementation, it is always better to start with a monolith;
- small team – it will take much longer to implement the system through microservices, it is better to start with a monolith.
Author: Andrey Efremov, head of the Java MTS IT center





