5 ways to crawl your website

Of Wikipedia web crawler or spider – a bot that crawls the World Wide Web, usually for indexing purposes. Search engines and other websites use crawlers to update their content or index the content of other sites.
Let’s start!!
Metasploit
The Metasploit Finder Helper is a modular crawler that will be used with wmap or stand alone.
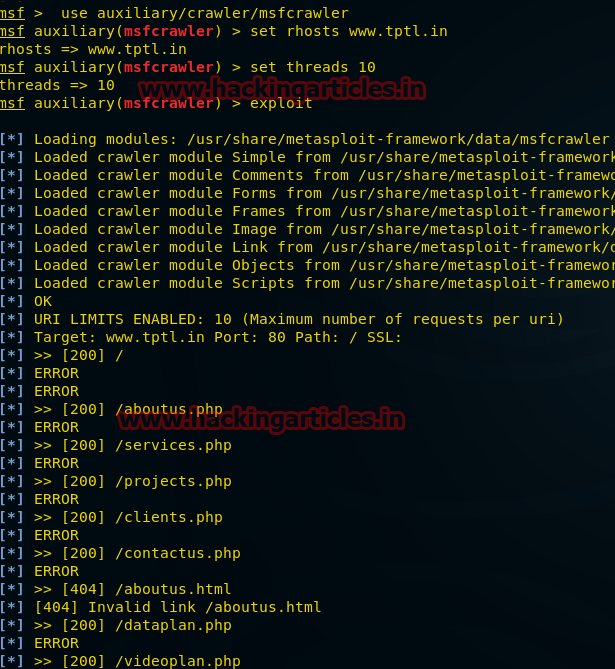
use auxiliary/crawler/msfcrawler
msf auxiliary(msfcrawler) > set rhosts www.example.com
msf auxiliary(msfcrawler) > exploitIt can be seen that a scanner has been launched, with which you can find hidden files on any website, for example:
Which cannot be done manually using a browser.
Httrack
HTTrack is a free open source crawler and standalone browser. It allows you to completely download a website by recursively building all directories
getting:
- Html
- Images
- other files
HTTrack orders the relative link structure of the source site.
Let’s enter the following command inside the terminal
httrack http://tptl.in –O /root/Desktop/fileIt will save the output to the given directory / root / Desktop / file

In the screenshot, you can see that Httrack has downloaded a lot of information about the website, among which there are many:
- html
- JavaScript files
Black Widow
It is a website downloader and offline browser. Detects and displays detailed information for a user-selected web page. BlackWidow’s intuitive interface with logical tabs is simple enough, but the abundance of hidden features may surprise even experienced users. Just enter the url you want and click Go. BlackWidow uses multithreading to quickly download all files and check links. For small websites, the operation takes only a few minutes.
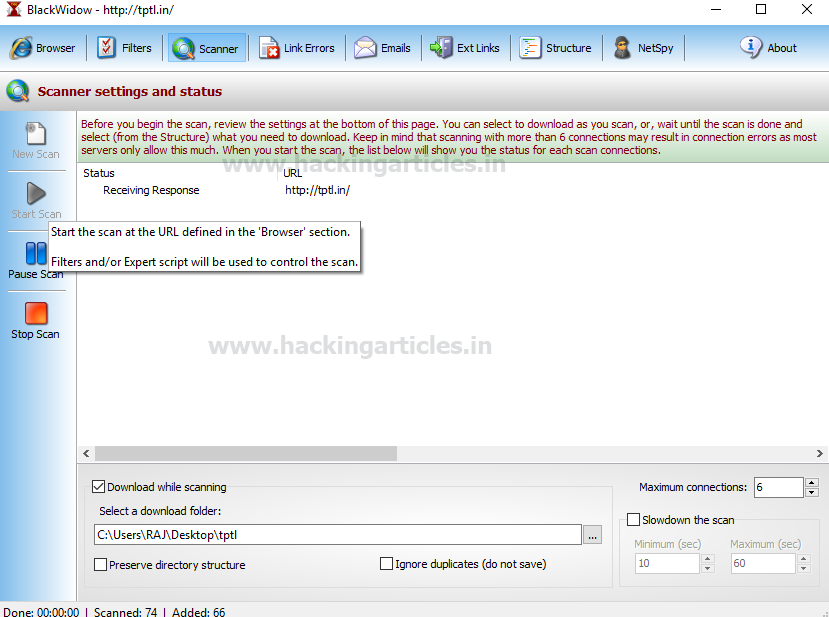
Let’s enter your URL http://tptl.in in the address field and click “Go”.

Click the “Start” button located on the left to start scanning URLs and select a folder to save the output file. In the screenshot, you can see that the C: Users RAJ Desktop tptl directory was browsed to save the output file there.
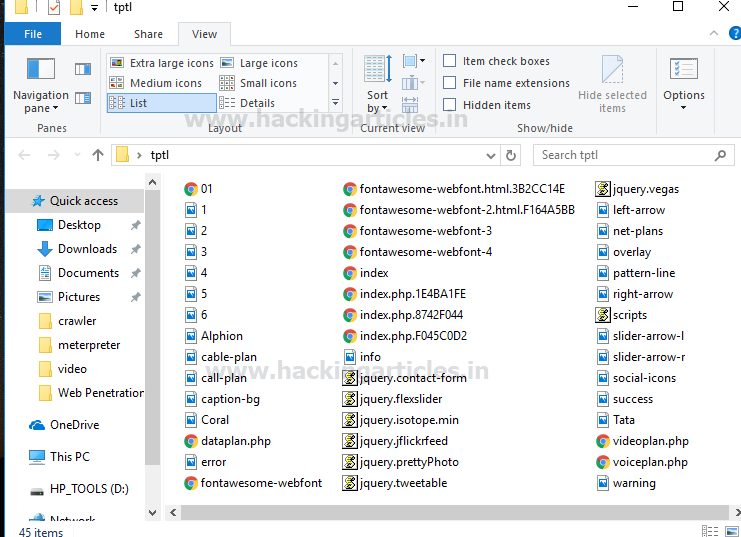
The tptl directory will now store all the website data:
- Images
- content
- html
- php
- JavaScript files
Website Ripper Copier
Website Ripper Copier (WRC) is a versatile high speed website downloader. WRC can download website files to local drive for offline viewing, extract website files of a specific size and type, such as:
- Images
- Video
- Audio
Also, WRC can extract large numbers of files as a resume-enabled download manager.
In addition, the WRC is a site link checker, explorer and tabbed web browser that prevents pop-ups. Website Ripper Copier is the only website download tool that can:
- resume interrupted downloads from:
- HTTP
- HTTPS
- FTP connections
- access sites that are password protected
- support web cookies
- analyze scripts
- update received sites or files
- run more than fifty extraction threads
You can download it here…
We select “websites for offline browsing”.
Enter the website url as http://tptl.in and click “next”.
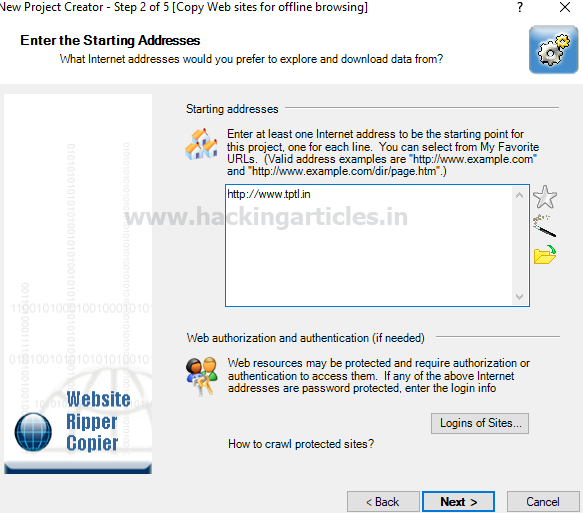
Specify the path to the directory to save the result, then click “run now”.
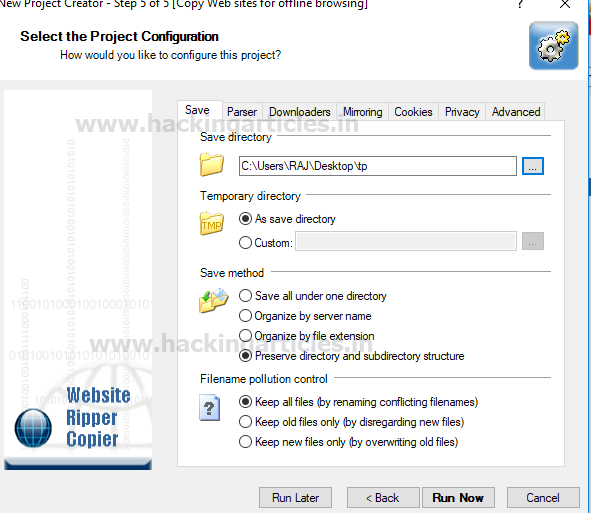
When you open the selected tp directory, there will be files inside it:
- CSS
- php
- html
- js
Burp suite spider
Burp Suite Spider is a tool for automatic scanning of web applications, which has already been written in more detail on habr. In most cases, it is desirable to display applications manually, but using Burp Spider this process can be automated, making it easier to work with very large applications or when there is a lack of time.
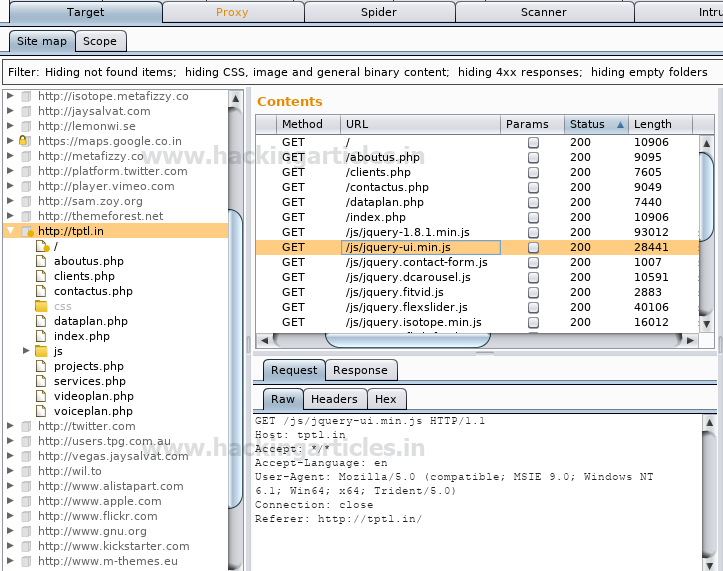
The screenshot shows that the http request was sent to the spider using the context menu.
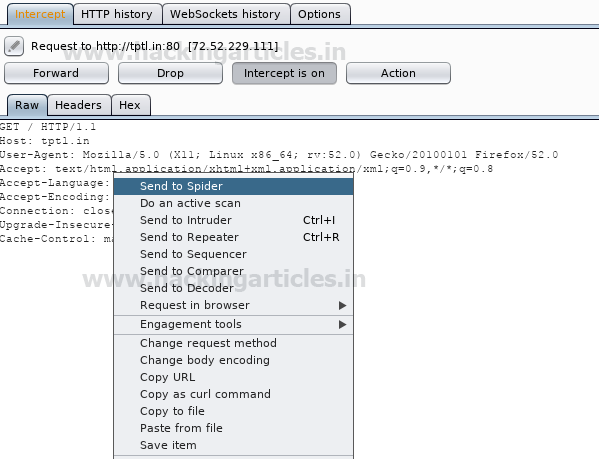
The website has been added to the sitemap under the target tab as a new area for web crawling, which has collected information in the form:
- Php
- Html
- Js