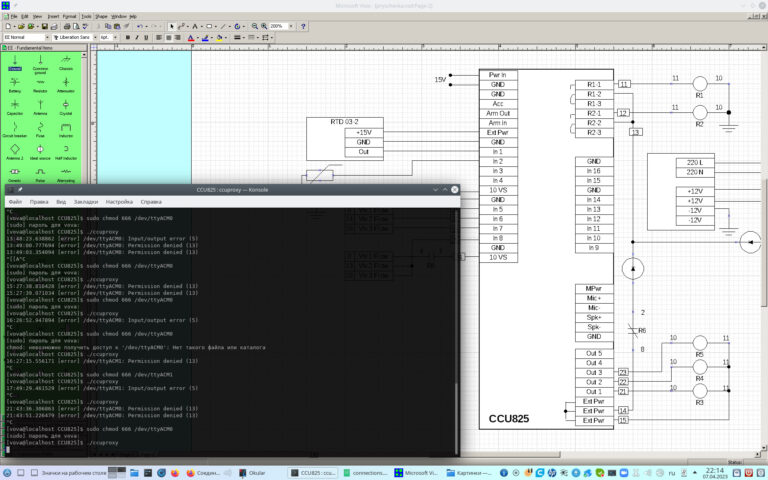
3D face reconstruction, or how to get your digital twin (Part 1)
 and rendering of a 3D model of the face (right)")
Let’s talk about one interesting method of restoring a 3D human face, which is almost indistinguishable from photographs.
For 2 years now, articles about facial 3D reconstruction have not appeared on Habré, and in Twin3D we want to gradually fill this gap and regularly post reviews of interesting articles, methods and our own results on the topic of 3D digital human in general.
First, a few words about who and why these 3D faces and bodies are needed (in general, you can write a separate article about this). Initially, 3D scanning of a person was used in cinema for special effects, where something little desirable in reality (for example, an explosion) or impossible should happen to the hero’s face. With the increasing requirements for graphics in computer games, there is a need to create more and more realistic characters – and it is much easier to scan a living person than to sculpt / draw from scratch from photographs. Now, to this is added the desire of people to be in the virtual world or to be characters in games themselves – and for this, of course, 3D models are also needed.
It is worth noting that previous articles on Habré focused on methods for easily creating 3D face models. As usual, there is a trade-off between quality and ease of obtaining a 3D model. In our series of articles, we will talk about 3 methods in descending order of complexity of the scanning process: from a special setup with 24 cameras and 6 flashes (we will talk about this method now) to photography from a smartphone.
Historically, face reconstruction began with standard multi-view stereo methods (you can read about this on Wikipedia, and there is also a cool brochure from Google), and it is clear that such methods require a large number of photographs from different angles. These methods are based on mathematical optimization.
Terminology
The result of basic 3D face reconstruction is the following combination: geometry + albedo texture + reflectivity and normals (pictures will be below).
Geometry Is just a mesh, i.e. an ordered collection of connected points in 3D.
Albedo texture Is essentially a set of pixels that cover this mesh, the actual skin color.
Reflectivity and normal map – information about each pixel about how it reflects the incident light (how much and in which direction).
Only in the presence of all these three components can you get a high-quality photorealistic 3D model of the face.
A few words about the method
The facial reconstruction method that we will now talk about is described in the article “Near-Instant Capture of High-Resolution Facial Geometry and Reflection” by G. Fyffe, P. Graham, B. Tunwattanapong, A. Ghosh, P. Debevec and presented at Eurographics 2016. You can read it here (further all pictures are taken from there). This work is notable for the fact that for the first time the authors managed to obtain the quality of restoration accurate to the pores of the skin with an almost instantaneous scan (66 ms). On the splash screen, you saw the results of this particular article. The article is already 5 years old, but it has become a kind of classic, and its authors are widely known in narrow circles (the same Debevec from Google). The article is written in a rather specific language and with the omission of many non-obvious details, so I had to break my head a little to understand it and write this text.
How it works
To begin with, the authors put together a very interesting rig of cameras and flashes. It has 24 Canon EOS 600D DSLR cameras and 6 Sigma EM-140 professional flashes. These flashes are switched on sequentially, and together with them, a subset of cameras are simultaneously photographed, so that in the end each camera takes pictures exactly once. Cameras are installed and divided into groups so as to optimally cover the entire face area and see at least 3 different reflections for each point (we’ll see why later). Implemented shooting using 80MHz Microchip PIC32 microcontroller. The authors thought separately that this whole process should take less than the blinking speed of a person (~ 100 ms), so 66 ms passes from the first to the last photo, according to the article.

The algorithm receives 24 photos and information about flashes as input, on the basis of this it creates a base mesh, and then, with the help of a little magic and mathematics, makes two maps of albedo and normal (diffuse and specular), on the basis of which a detailed mesh is obtained with an accuracy of pores and wrinkles.

The original mesh is obtained through the usual multiview stereo (for example, Metashape). But its quality is quite low (+ – 2 mm), so based on the normal map, this mesh is refined at the end.

The algorithm is based on photometric stereo – a set of computer vision methods, in which not only the photographs themselves are used, but also information about the incident light: the intensity and direction of the light. This approach allows us to understand how a particular pixel in a texture reflects light in different conditions, which is especially important for human skin. As I mentioned above, the algorithm produces two normal maps. The first – diffuse – corresponds to a matte reflection of the face, that is, reflections from the deep layers of the skin. The second – specular – is needed to render the smallest details of the skin’s surface.

And these normals are obtained for each pixel, in fact, through the solution of systems of linear equations

Where L – matrix of light directions for all types of cameras, beta – required normal (3-dimensional vector), P – conventional pixel values for these points and camera views. After a close look at this system, it becomes clear why it is necessary to see the point from at least three angles – otherwise the system cannot be solved unambiguously. If you want to have a 4096×4096 resolution card, you need to solve 16 million such systems, so efficient use of the GPU is a must have here. Parallelization of such computations is a separate non-trivial task.
These equations are solved within the framework Lambert approximation for diffuse normals, because this is exactly what is needed to describe the matte reflection of the skin from its deep layers. For specular normals, more complex equations are solved in Approaching Blinn-Phongto account for the possibility of specular skin reflections, but the essence remains the same.
results
If you have a refined mesh, albedo, illumination and normal maps, you can render a 3D model of the face under an arbitrary angle and lighting.
Let’s start by comparing a chunk of the cheek of a photo and rendering under the same angle and lighting. As you can see in the picture below, the results are very accurate down to the smallest pores and light reflections.
 and rendering of a 3D model at the same angle and lighting (right)")
If we look at rendering from a new angle and lighting, then everything is pretty decent here too.

Outcomes
For all the coolness of the result and method, of course, the result is not a super-perfect human avatar. Several key elements are not processed here in any way:
Hair – in all the results, people just wear hats, no one has stubble
Selected artifacts – ears, nostrils of the nose and other poorly visible places are not processed in any special way
Eyes – they are certainly not suitable for games or movies 🙂
IN Twin3D we are also working on algorithms for photorealistic face and body reconstruction; have assembled our own rig, in which we can scan a face using both classical photogrammetry and stereo photometrics. We believe that such approaches can and should be inspired, but ultimately, in order to obtain photorealistic digital people without artifacts, an element of learning from data is needed, because the classical approach does not understand that the nostrils and eyes need to be processed somehow differently than the skin. We will discuss approaches with learning elements in future articles.